登顶行业SOTA的多模态视频生成标杆,昆仑天工刚给开源了
登顶行业SOTA的多模态视频生成标杆,昆仑天工刚给开源了好家伙,AGI真的「Open」了我的生活。(doge)
来自主题: AI资讯
7244 点击 2026-01-30 10:39
 搜索
搜索
好家伙,AGI真的「Open」了我的生活。(doge)

AI 网红们在社交平台上混得风生水起。

人类幻想中所有带着陪伴属性的小精灵,都不约而同地飞在空中。
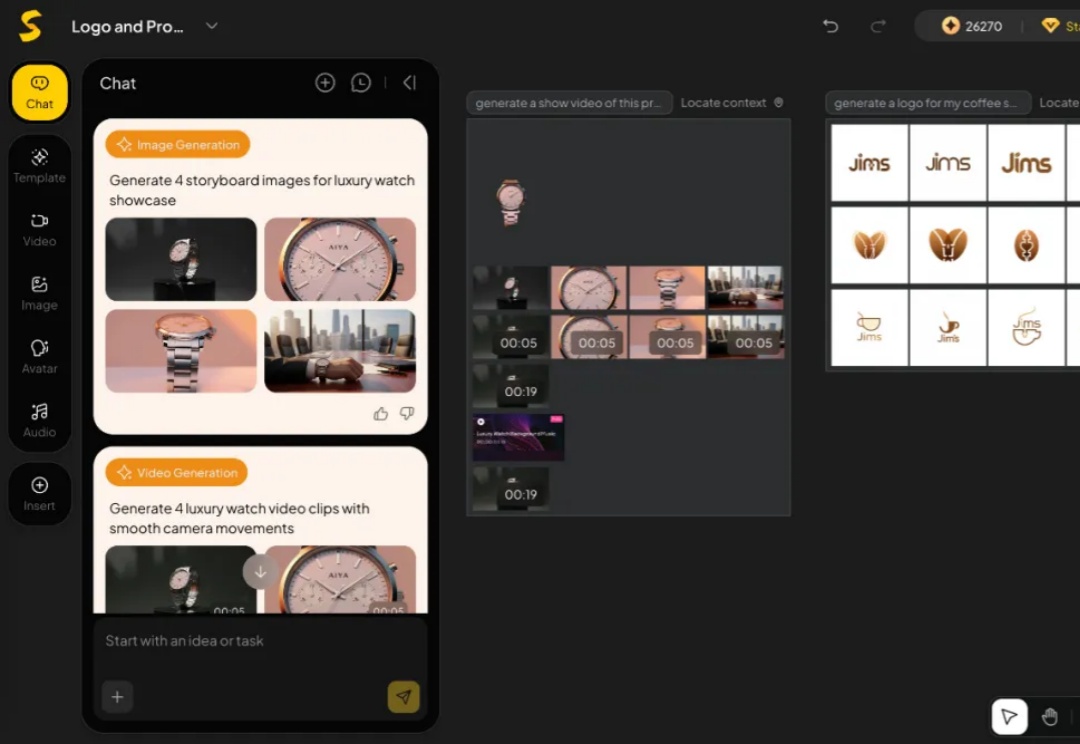
视频生成快速演进的脚步仍未停歇,就在今天,昆仑万维的新动作又一次突破行业想象。
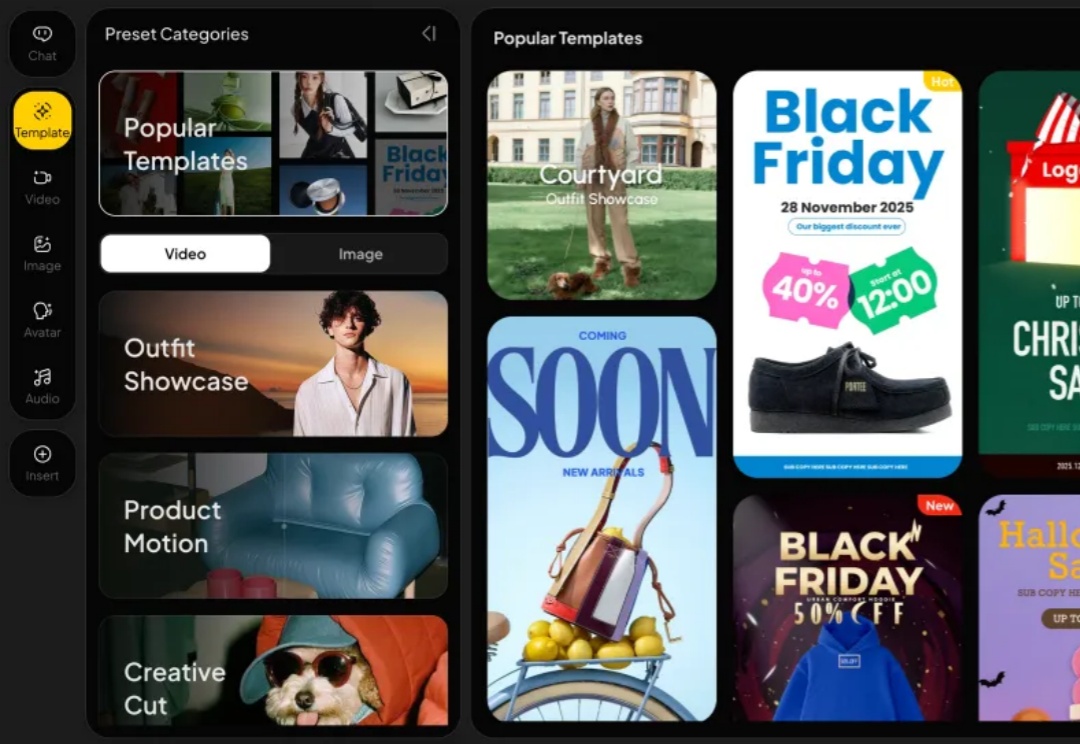
这两天有只企鹅在网上火到不行,不知道大家刷没刷到,穿的一本正经,但神态却贼抽象,长这样:

OpenAI全新收购曝光,曾为Mac开发自然语言交互界面——Sky——的公司如今成了GPT生态的一员。作为交易的一部分,OpenAI将把Sky的技术整合进ChatGPT,并吸纳这支约12人的团队。

当OpenAI为ChatGPT各种造势时,中国模型也在凭实力圈粉老外。最近,爱彼迎(Airbnb)联合创始人兼CEO Brian Chesky的一番公开表态掀起波澜:要知道Brian Chesky和奥特曼还是挚友,但当涉及自家应用产品整合时,他却没给老朋友留面子,直言OpenAI提供的连接工具还“没有完全准备好”。
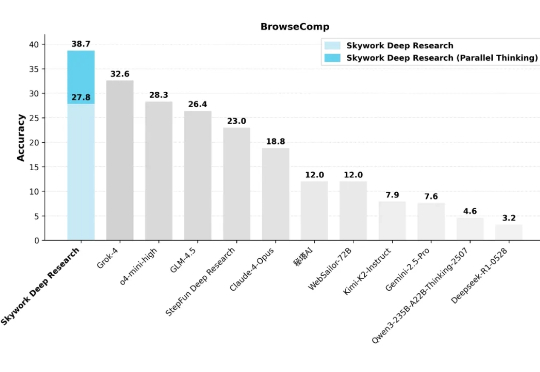
疯狂的七月已经落下了帷幕,如果用一个词来形容国产大模型,「开源」无疑是当之无愧的高频词汇。
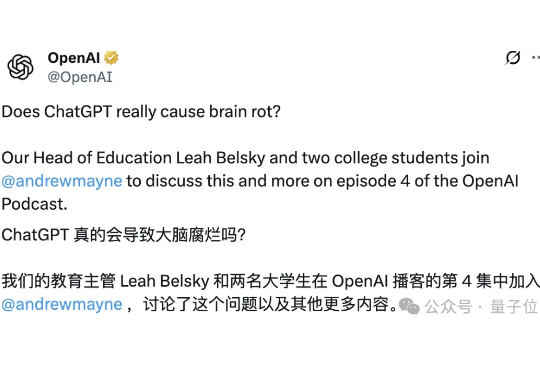
ChatGPT用多了会变傻?官方回应来了! OpenAI教育主管Leah Belsky明确表示:AI本质上是一个工具,关键在于如何使用它。

听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。