
Cell重磅!微软开源首个AI肿瘤免疫模型,仅需几美元成本,一键看穿癌症底细!
Cell重磅!微软开源首个AI肿瘤免疫模型,仅需几美元成本,一键看穿癌症底细!AI与医学的深度融合,为健康领域的进步创造了前所未有的机遇。
来自主题: AI资讯
9219 点击 2025-12-12 10:29
 搜索
搜索
AI与医学的深度融合,为健康领域的进步创造了前所未有的机遇。
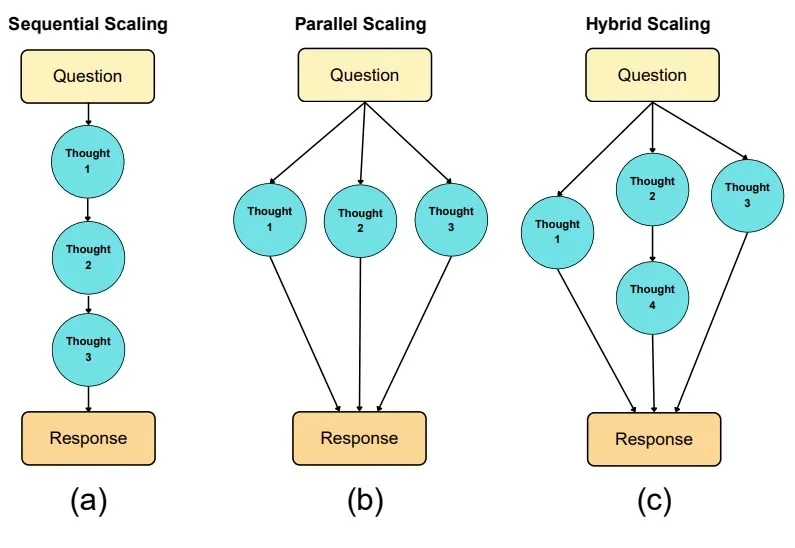
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

大家好,我是袋鼠帝。 今天想跟大家聊聊最近很火的一个新概念:GEO

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。
来自AI语音独角兽公司ElevenLabs,刚刚发布了Scribe v2 Realtime实时语音转文本模型,网友表示:Next-Level。150毫秒的超低延迟,93.5%的高准确率,还覆盖了90多种语言。
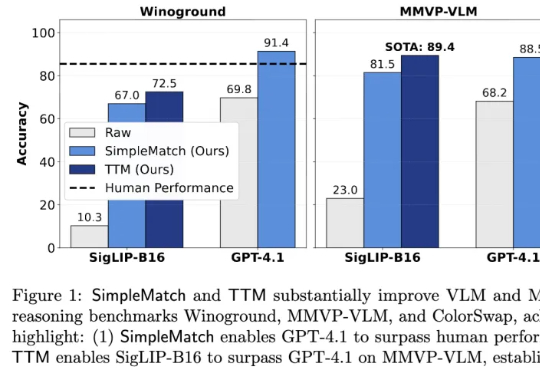
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。
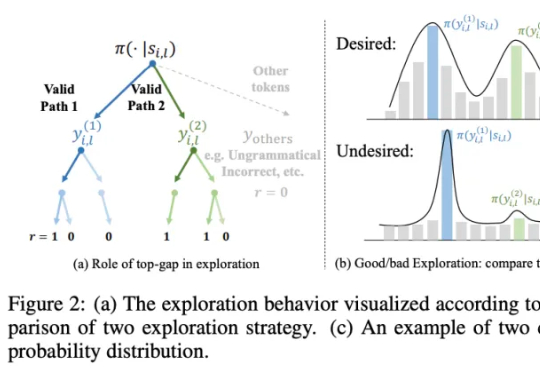
研究团队提出一种简洁且高效的算法 ——SimKO (Simple Pass@K Optimization),显著优化了 pass@K(K=1 及 K>1)性能。同时,团队认为当前的用熵(Entropy)作为指标衡量多样性存在局限:熵无法具体反映概率分布的形态。如图 2(c)所示,两个具有相同熵值的分布,一个可能包含多个峰值,而另一个则可能高度集中于一个峰值。