多模态幻觉的病因「高熵节点」找到了!全基准幻觉率下降
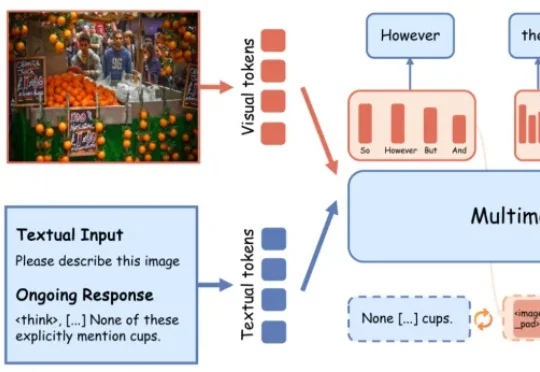
多模态幻觉的病因「高熵节点」找到了!全基准幻觉率下降多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。
来自主题: AI技术研报
9428 点击 2026-04-11 09:37