
DeepMind核心论文禁发6个月,Transformer级研究锁死!CEO:不满意就走人
DeepMind核心论文禁发6个月,Transformer级研究锁死!CEO:不满意就走人DeepMind内部研究要「封箱」了!为保谷歌在AI竞赛领先优势,生成式AI相关论文设定6个月禁发期。不仅如此,创新成果不发,Gemini短板不提。
来自主题: AI资讯
8765 点击 2025-04-02 15:10
 搜索
搜索
DeepMind内部研究要「封箱」了!为保谷歌在AI竞赛领先优势,生成式AI相关论文设定6个月禁发期。不仅如此,创新成果不发,Gemini短板不提。

「仅需一次前向推理,即可预测相机参数、深度图、点云与 3D 轨迹 ——VGGT 如何重新定义 3D 视觉?」
在过去的一两年中,Transformer 架构不断面临来自新兴架构的挑战。

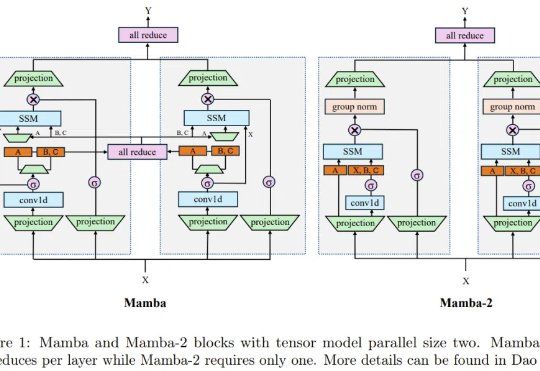
首个基于混合Mamba架构的超大型推理模型来了!就在刚刚,腾讯宣布推出自研深度思考模型混元T1正式版,并同步在腾讯云官网上线。对标o1、DeepSeek R1之外,值得关注的是,混元T1正式版采用的是Hybrid-Mamba-Transformer融合模式——

谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。
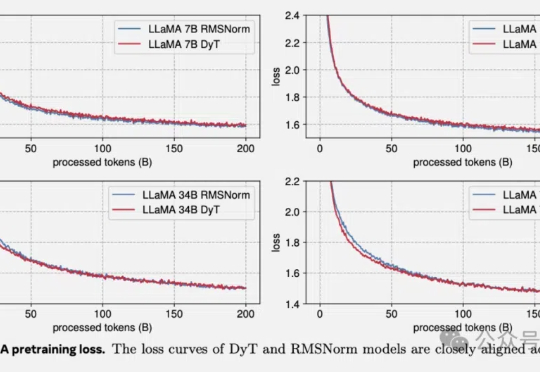
何恺明LeCun联手:Transformer不要归一化了,论文已入选CVPR2025。

Transformer架构迎来历史性突破!刚刚,何恺明LeCun、清华姚班刘壮联手,用9行代码砍掉了Transformer「标配」归一化层,创造了性能不减反增的奇迹。

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。
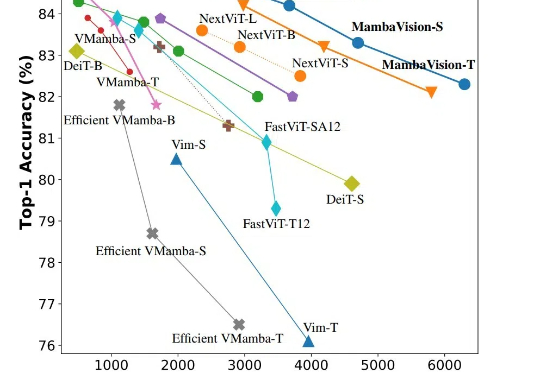
CVPR 2025,混合新架构MambaVision来了!Mamba+Transformer混合架构专门为CV应用设计。MambaVision 在Top-1精度和图像吞吐量方面实现了新的SOTA,显著超越了基于Transformer和Mamba的模型。