想入局VLA却不知从何下手?NTU&中大开源「终极菜谱」:从基座到频域建模,每一步都有实验支撑
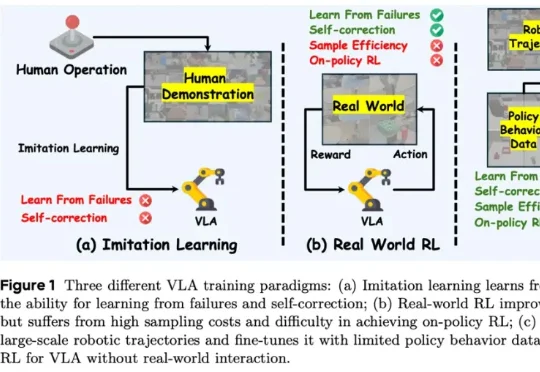
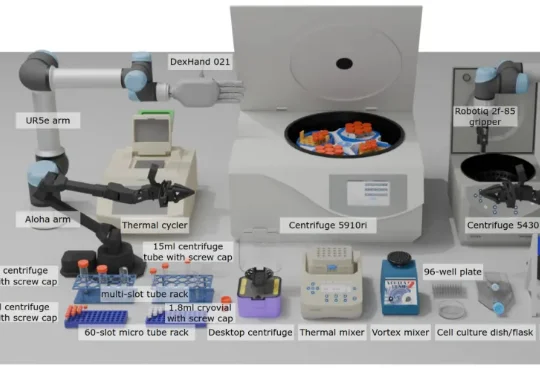
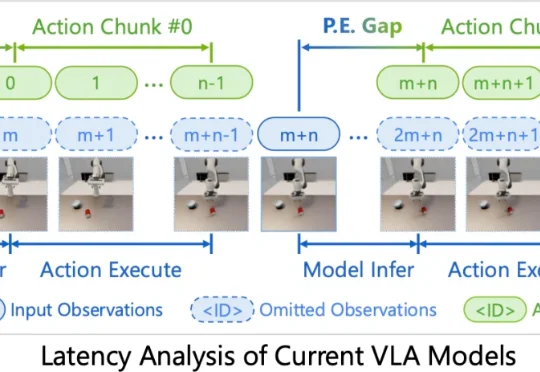
想入局VLA却不知从何下手?NTU&中大开源「终极菜谱」:从基座到频域建模,每一步都有实验支撑MMLab@NTU联合中山大学的最新研究,给出了一份从入门到精通的终极“菜谱”——VLANeXt。这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。
来自主题: AI技术研报
8585 点击 2026-03-03 10:44