北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型
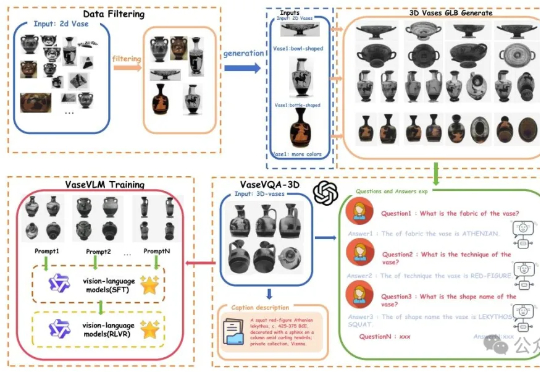
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
来自主题: AI技术研报
9274 点击 2025-11-07 14:49
 搜索
搜索
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
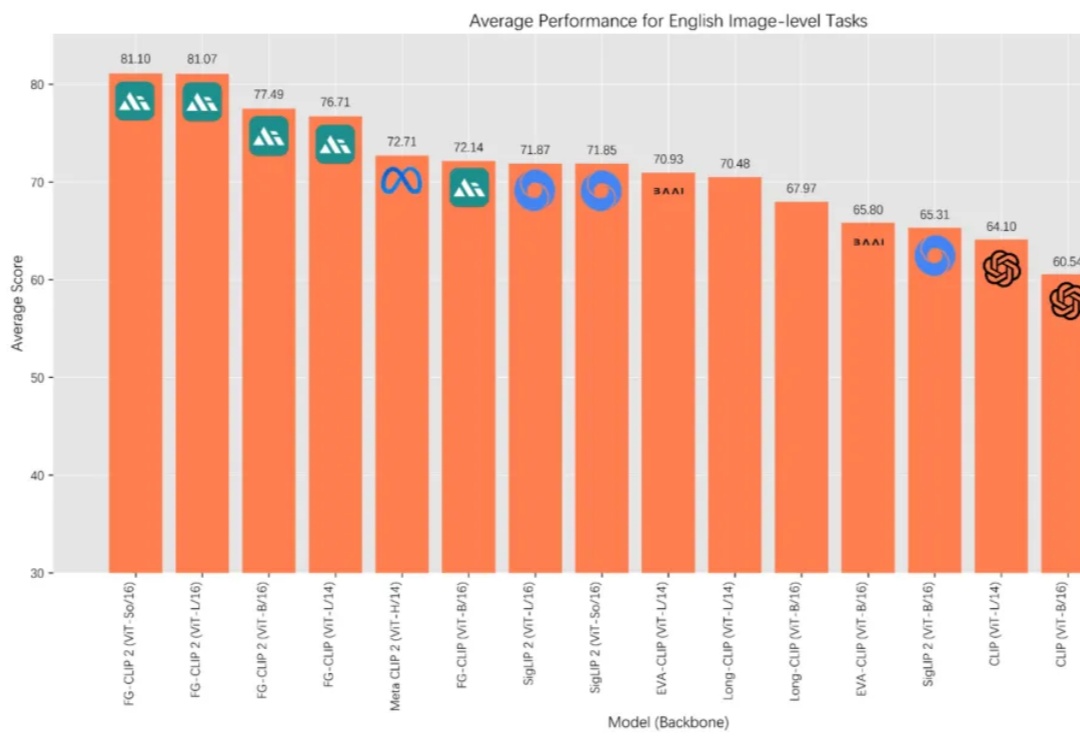
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
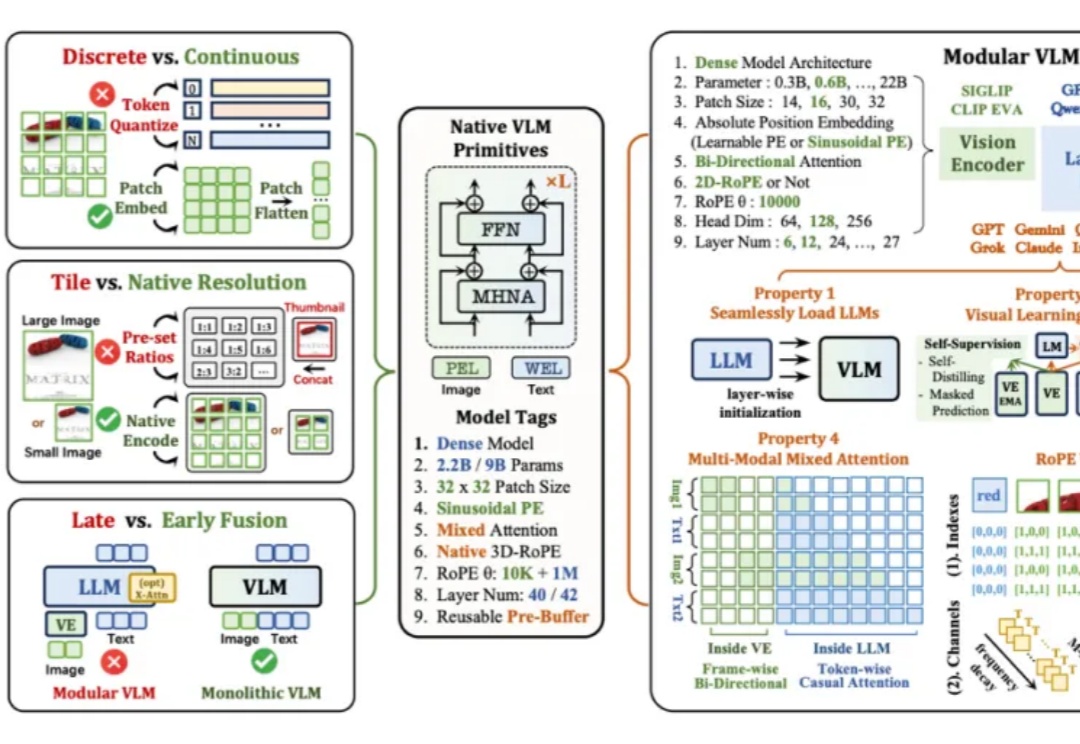
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。

当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
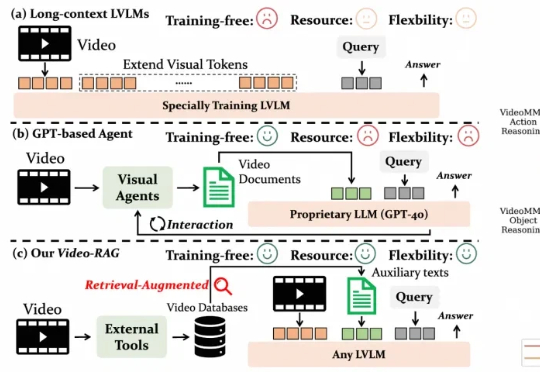
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
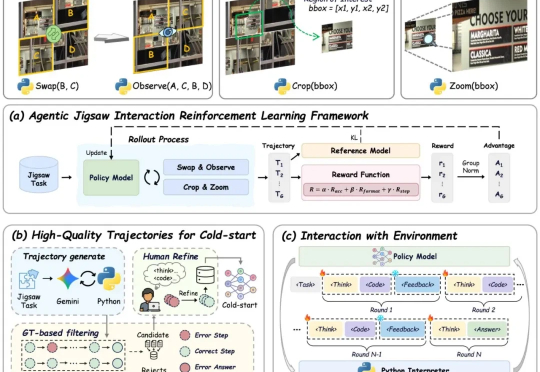
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
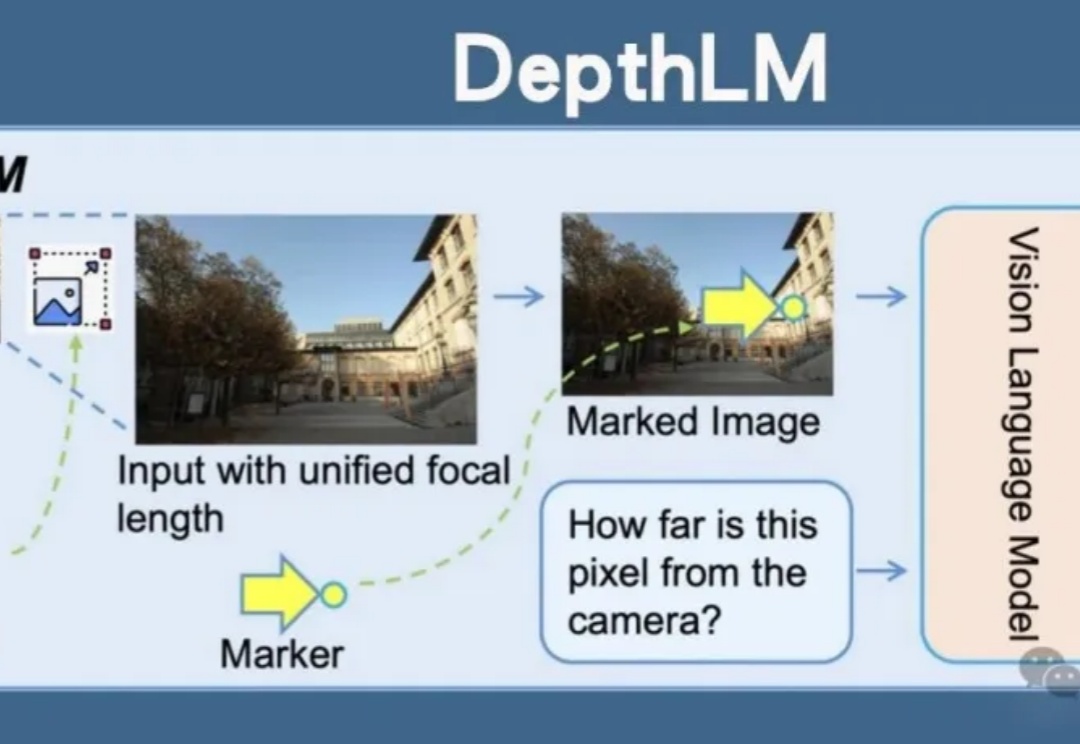
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
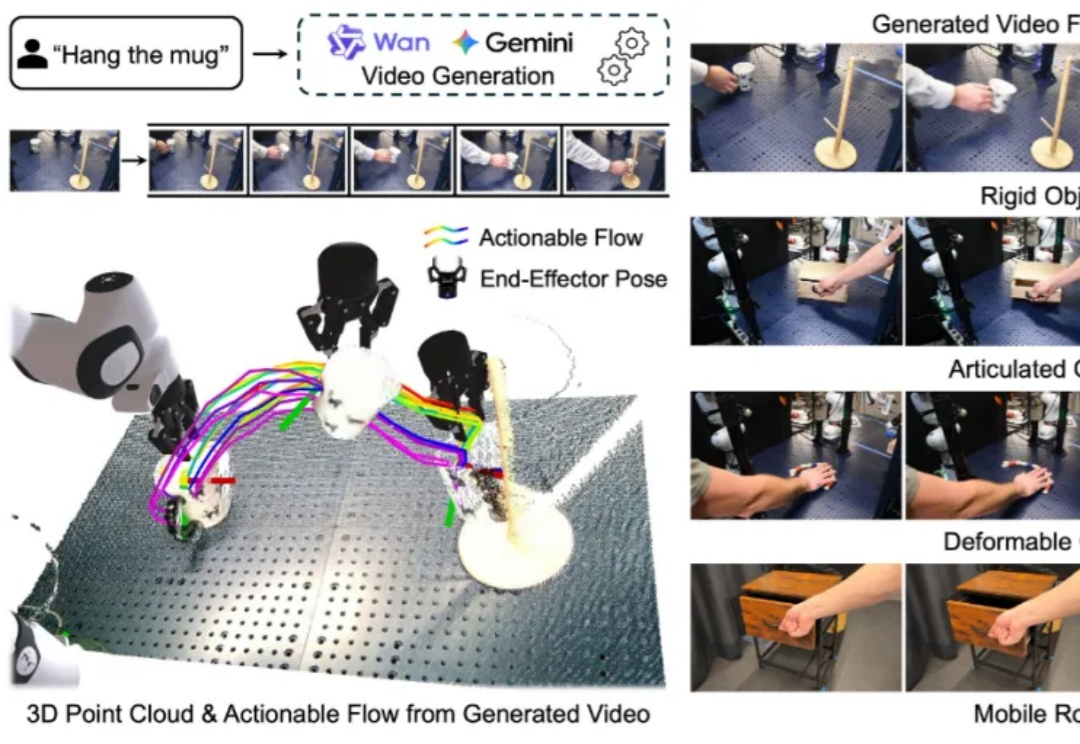
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。