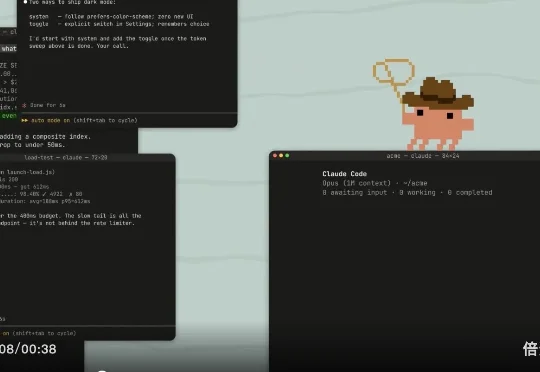
Claude Code推出Agent视图,一屏管所有,再也不用盯着几十个终端窗口!
Claude Code推出Agent视图,一屏管所有,再也不用盯着几十个终端窗口!Claude Code今天正式推出Agent视图功能,让用户在一个界面里统一管理所有Claude Code会话。此前并行运行多个Agent时,开发者往往需要同时维护多个终端标签页、一个tmux网格,还得靠脑子记住每个任务的进度。
来自主题: AI资讯
9550 点击 2026-05-12 12:03
 搜索
搜索
Claude Code今天正式推出Agent视图功能,让用户在一个界面里统一管理所有Claude Code会话。此前并行运行多个Agent时,开发者往往需要同时维护多个终端标签页、一个tmux网格,还得靠脑子记住每个任务的进度。
最近很多人也在问我,我用Agent,是怎么跟很多数据进行交互的。其实很多的交互,都是我让Claude Code直接跟飞书进行交互的,包括我们公司小伙伴也是,大家用图形化界面的时间占比,反而变得越来越少了。
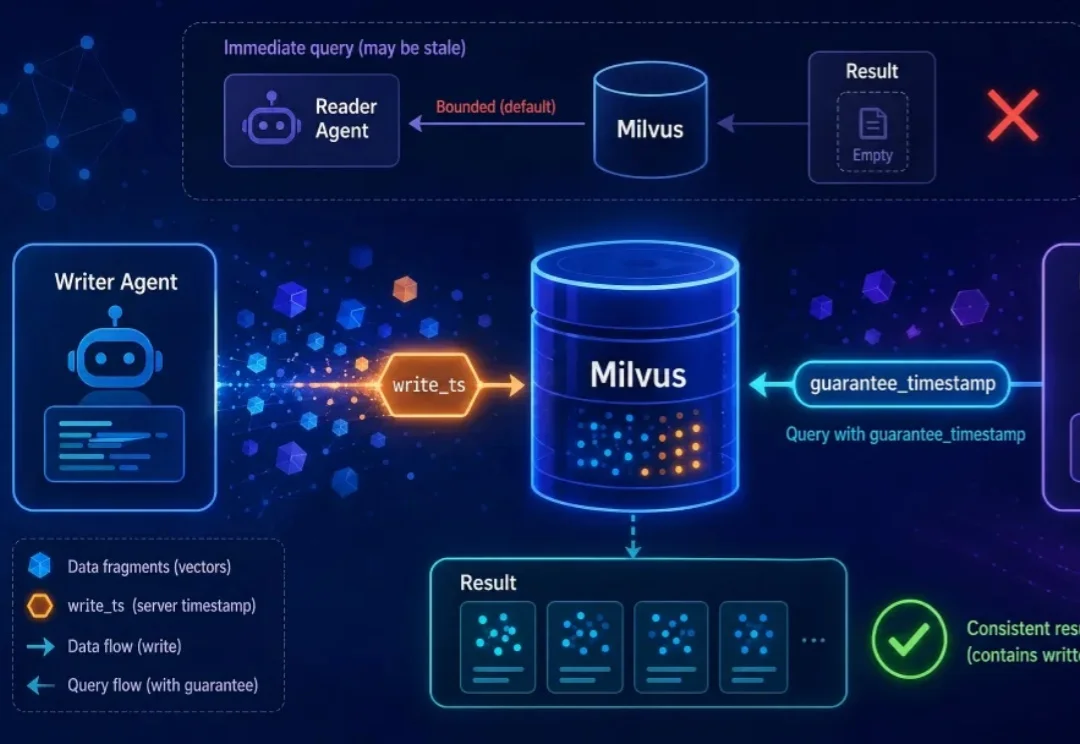
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。

这是一个“等待被大厂吞没”的行业,还是可能长出像Adobe那样的工具型公司?

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。

飞拓星驰(FitX AI)宣布完成数百万美金融资,由日初资本领投,光点资本跟投。这笔融资将用于Fit-OS空间智能 Agent 平台的研发,以及首款客厅 AI Native 终端的量产准备——预计 2027 年 CES 全球首发。

Slock是一个号称AI版Slack的AI群聊。基本形态是一个群聊网页,你首先要接入自己本地电脑的Agent,再把他们拉到一个群里。然后就可以像在工作群指挥人一样,指挥你的Agent们干活啦。
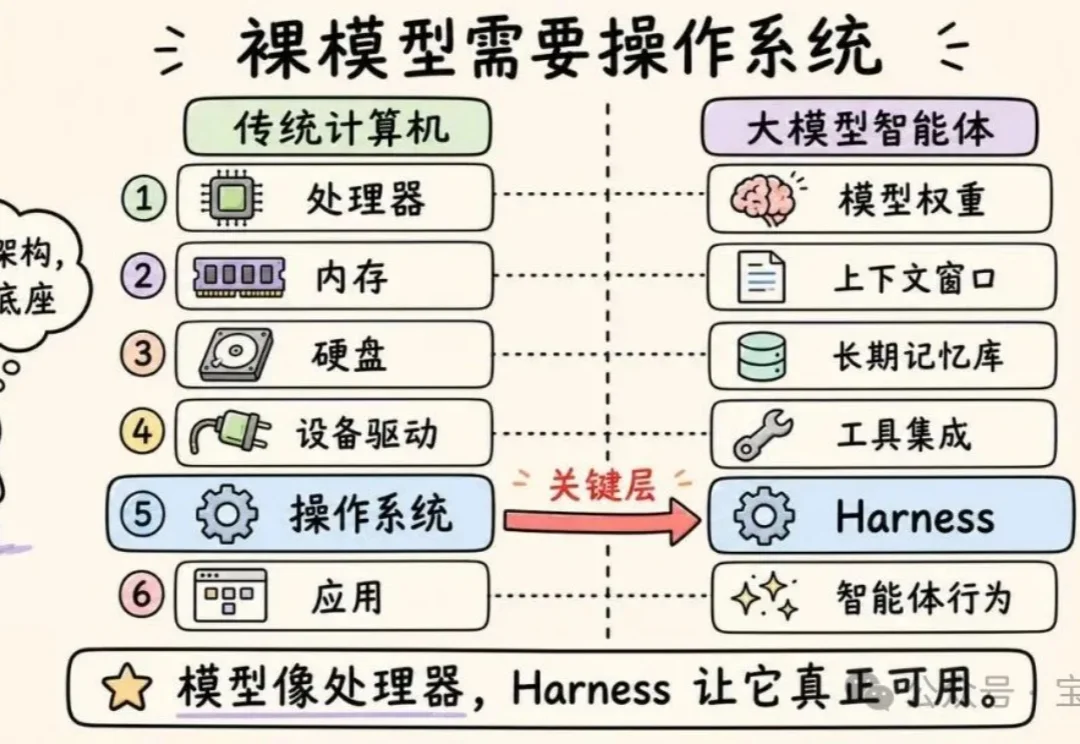
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
我看到洛小山做的 Alice,在「观猹」上取得了高分 8.2 的成绩。这是一个免费的 AI 个人助理(接入词元跳动注册即送免费算力):她有完整的人设,26 岁澳门女生,会在凌晨提醒你早睡,还会私下「小声蛐蛐」对你的观察。

AI硬件公司未来智能宣布完成亿元级A+轮融资,参投方是在全球手机市场中素有“非洲之王”称号的传音。据未来智能CEO马啸透露,这轮融资很快就完成了敲定,“我们没有盲目融很多钱,而是按照公司的发展需要去规划。”