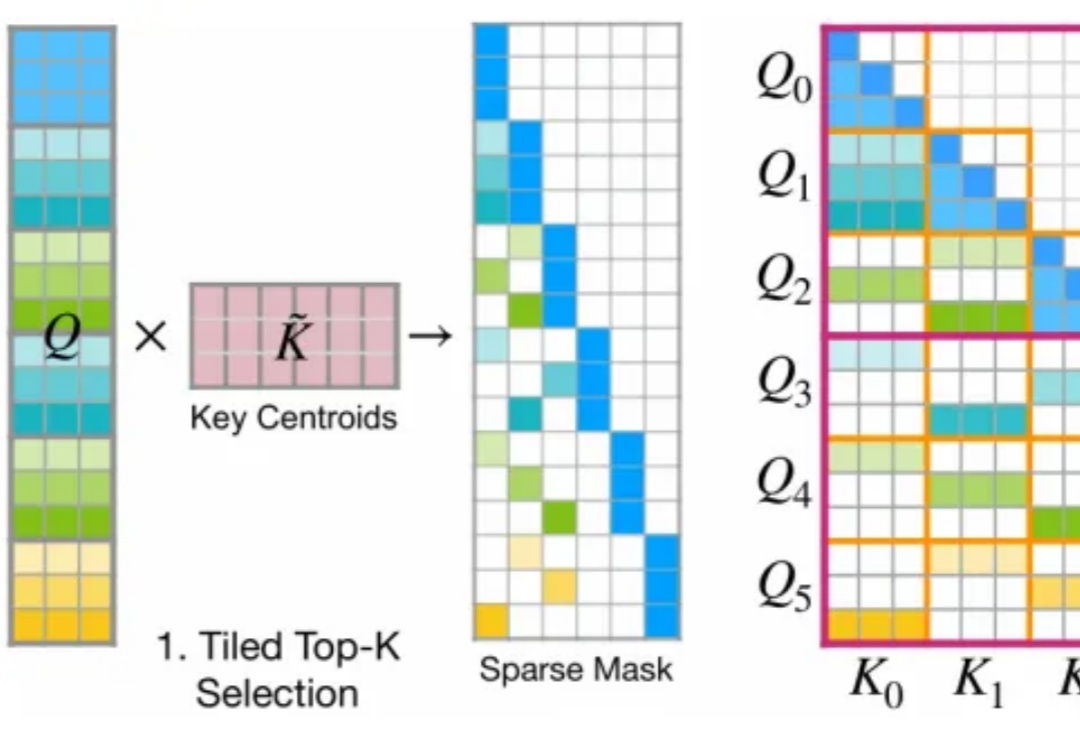
韩松等提出FlashMoBA,比MoBA快7.4倍,序列扩到512K也不会溢出
韩松等提出FlashMoBA,比MoBA快7.4倍,序列扩到512K也不会溢出今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
来自主题: AI技术研报
11022 点击 2025-11-18 15:15
 搜索
搜索
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),
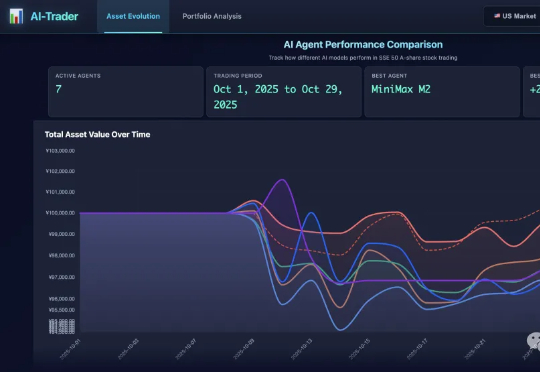
屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。
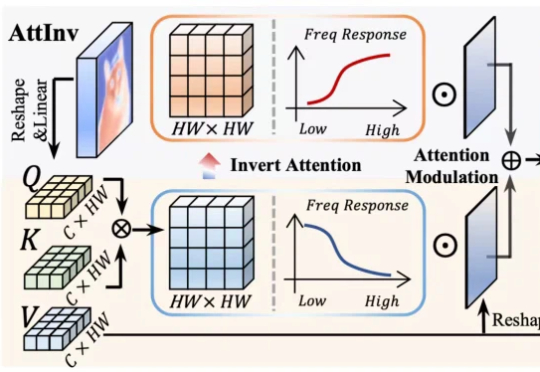
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。

英伟达还能“猖狂”多久?——不出三年! 实现AGI需要新的架构吗?——不用,Transformer足矣! “近几年推理成本下降了100倍,未来还有望再降低10倍!” 这些“暴论”,出自Flash Attention的作者——Tri Dao。
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。
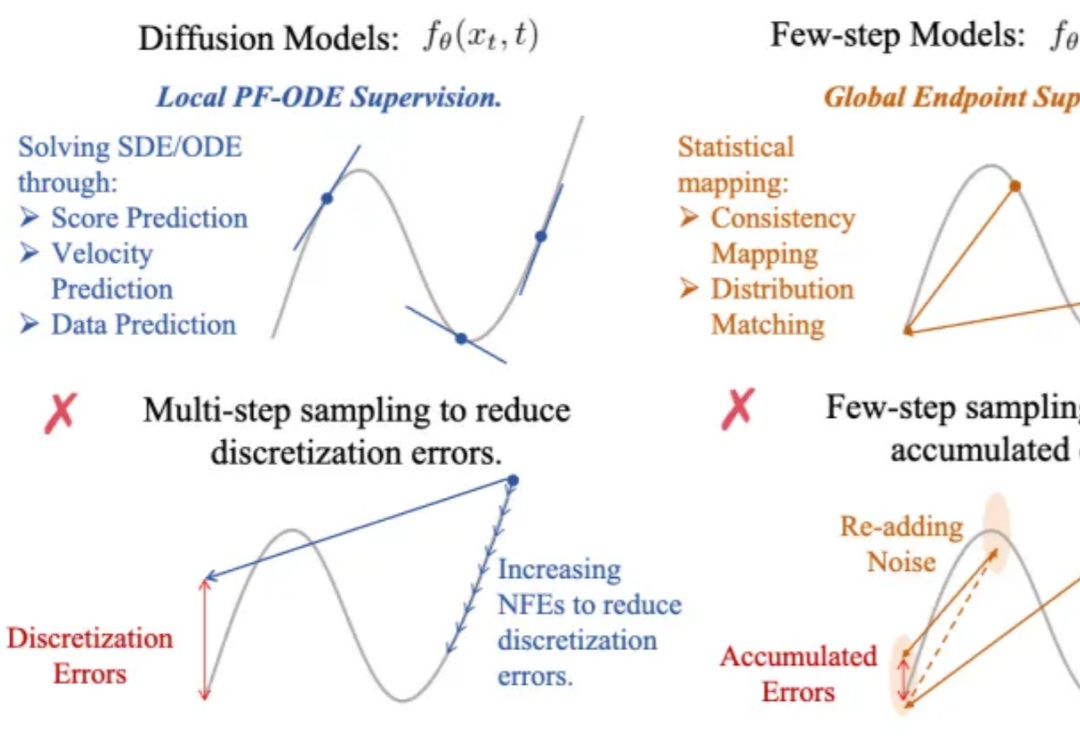
生成式AI的快与好,终于能兼得了?
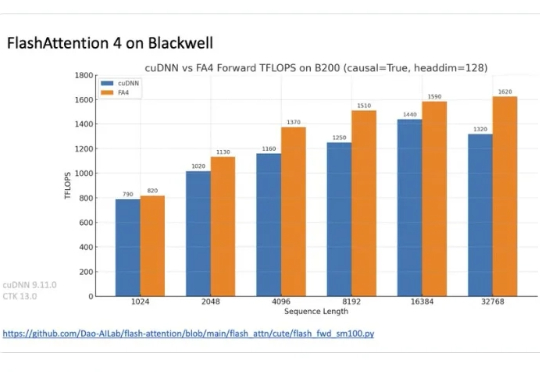
在正在举办的半导体行业会议 Hot Chips 2025 上,TogetherAI 首席科学家 Tri Dao 公布了 FlashAttention-4。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。