
AI图像革命才刚刚开始
AI图像革命才刚刚开始本期AGI路线图中关键节点:DiT架构、Stable Diffusion 3.0、Flux.1、ControlNet、1024×1024分辨率、医学影像、英伟达Eagle模型、谷歌Med-Gemini系列模型、GPT-4o端到端、Meta Transfusion模型。
来自主题: AI资讯
6901 点击 2024-10-10 11:42
 搜索
搜索
本期AGI路线图中关键节点:DiT架构、Stable Diffusion 3.0、Flux.1、ControlNet、1024×1024分辨率、医学影像、英伟达Eagle模型、谷歌Med-Gemini系列模型、GPT-4o端到端、Meta Transfusion模型。
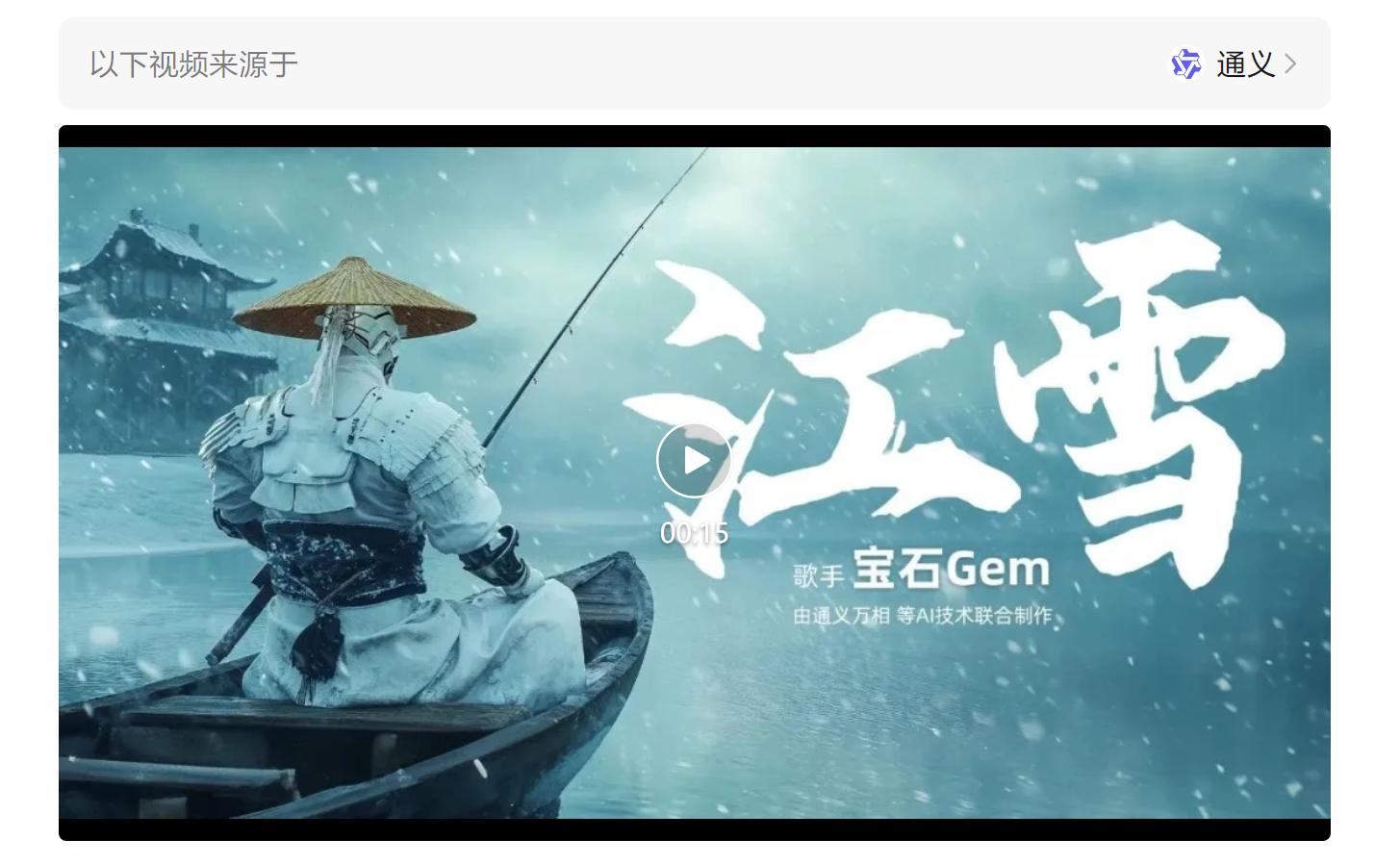
阿里放大招了,就在刚刚,通义万相AI视频功能正式开放。5秒的视频,在手机端APP不限次数免费用!连今晚音乐节的MV都是AI直出。试用后我们惊喜地发现,更懂中国风的AI视频,它真的来了。

这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。
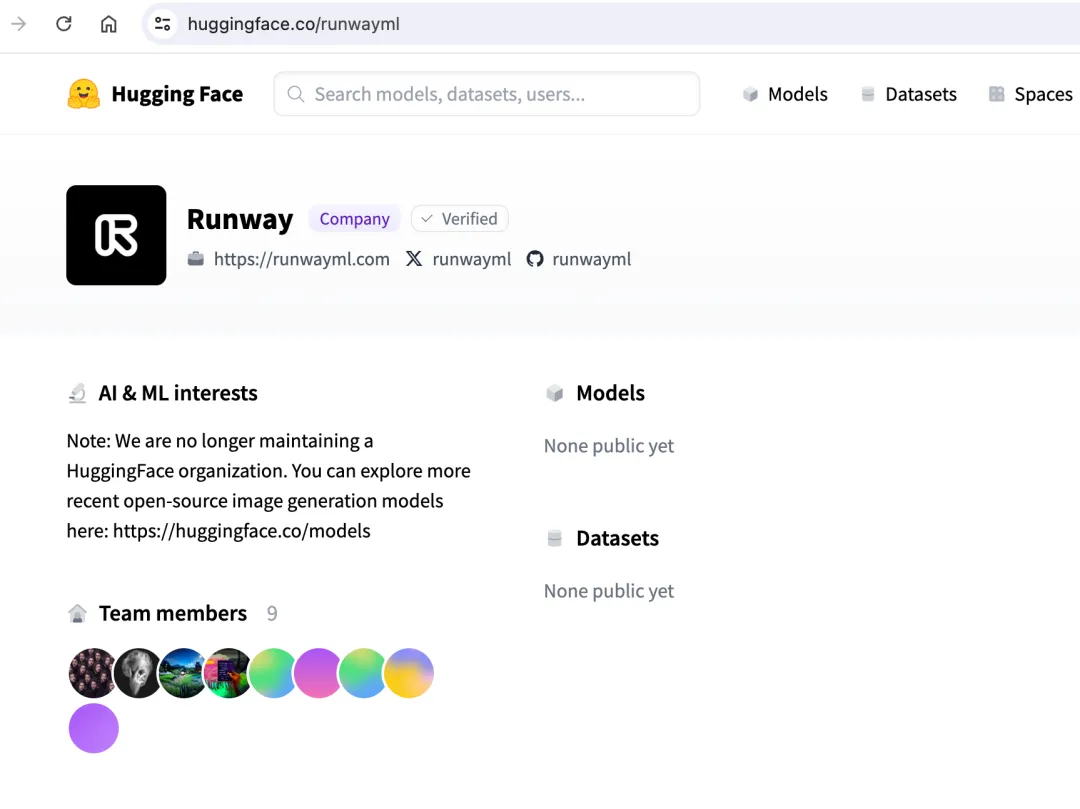
没有任何通知,Runway在Hugging Face上的内容全部删除了!

本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。

就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!

大家还记得 Stable Diffusion嘛,就是那个曾经和 DALL·E 、 Midjourney 齐名的图像生成 AI 。
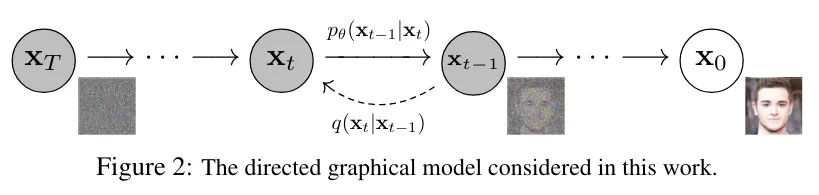
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。

也许视觉模型离AGI更近。