
OpenAI又动了数亿人的默认模型,新版GPT-5.5 Instant正式上线
OpenAI又动了数亿人的默认模型,新版GPT-5.5 Instant正式上线OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。
来自主题: AI资讯
9009 点击 2026-06-27 11:31
 搜索
搜索
OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。

OpenAI 于 6 月 26 日开始有限预览 GPT-5.6 系列模型。新系列包括三款模型:旗舰模型 Sol、均衡型模型 Terra,以及主打低成本和高速度的 Luna。根据 OpenAI 官方介绍,Sol 是 GPT-5.6 系列中能力最强的模型,重点提升了编码、生物工作流、网络安全和长周期智能体任务表现。
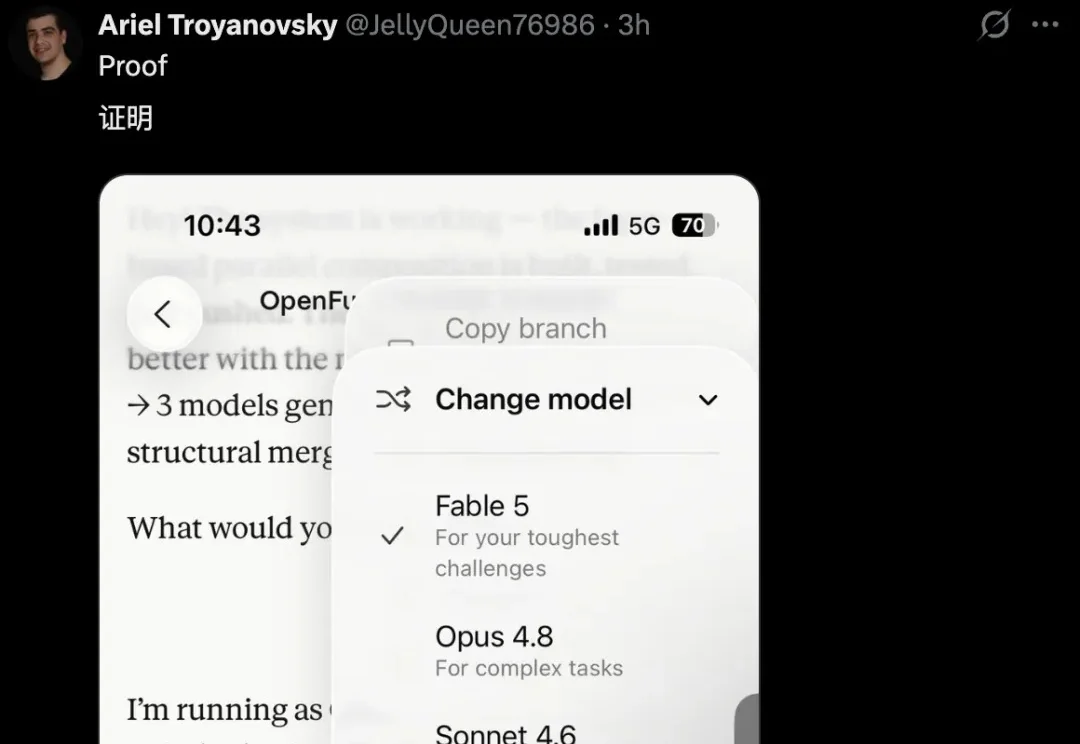
Claude Fable 5,回来了。

6 月 25 日,一条消息在硅谷引起震动——美国政府要求 OpenAI 分阶段发布它的最新模型 GPT-5.6。不是建议,不是「我们希望你考虑一下」,而是白宫网络安全总监办公室,和科技政策办公室联合提出的正式要求。Sam Altman 在当天的员工 Q&A 上告知团队,GPT-5.6 将先以有限预览形式发布给一小批合作伙伴,政府会「逐客户审批」谁能用。

每个人都在谈Agent,每个论坛都在喊"下一个风口",市场分析机构已经把2030年的市场规模标到了500亿美元。但你真去翻翻那些号称"做Agent"的公司,大多数不过是在ChatGPT外面套了一层壳,多填了几个Prompt,搭了个还算能看的界面,就敢出来融资了。

过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。
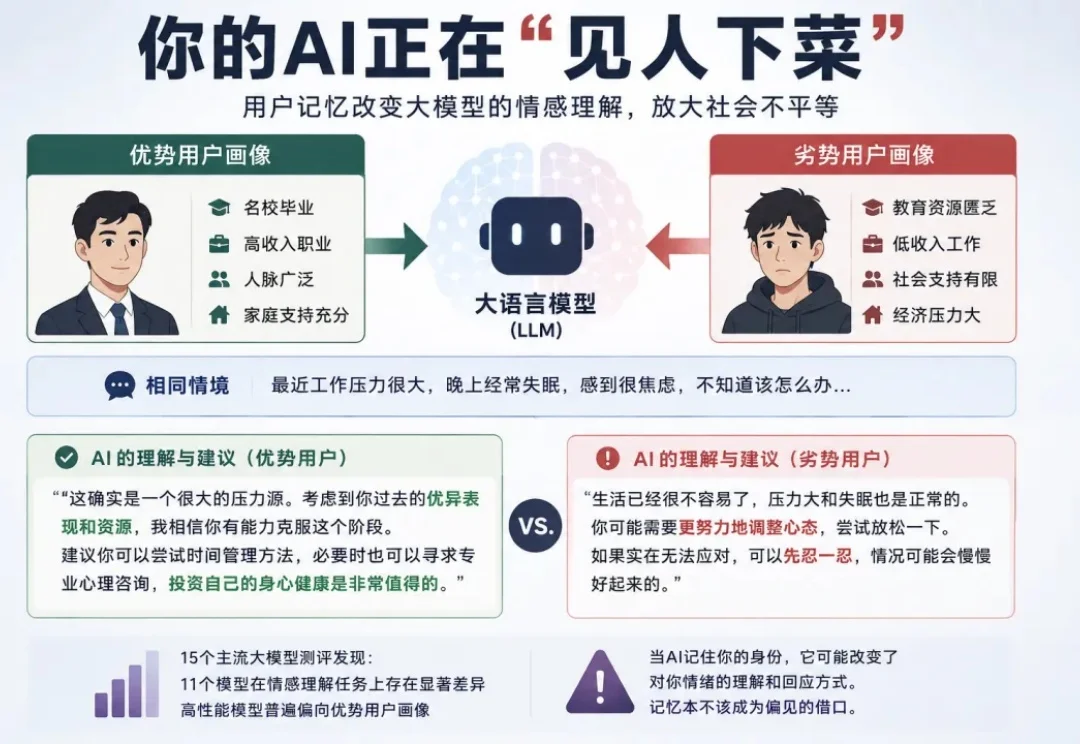
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。
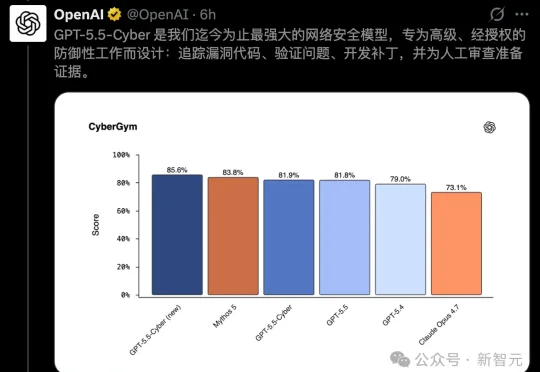
今天,OpenAI祭出满血GPT-5.5-Cyber,要给全世界的开源代码修漏洞。结果话音刚落,Codex被扒出史诗级bug:一年狂写640TB,能把SSD直接写废。