
刚刚,GPT-5.5被星火医疗大模型V3.5反超了!
刚刚,GPT-5.5被星火医疗大模型V3.5反超了!刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
来自主题: AI资讯
10364 点击 2026-06-14 12:52
 搜索
搜索
刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
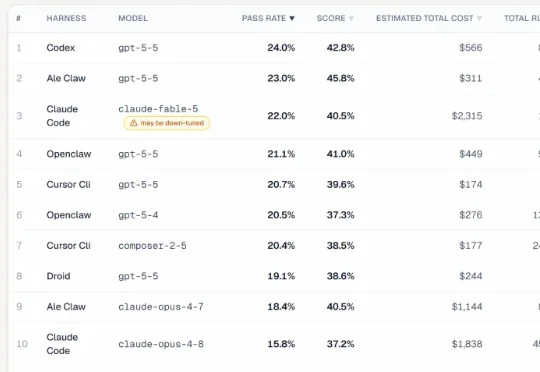
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
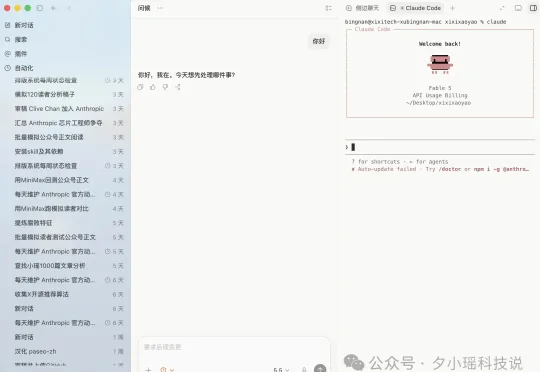
所以,教你一招把Claude code塞进Codex里。所以我现在的工位长这样——左边是 GPT,右边跑着 Claude Code,同一个窗口。Codex负责管规划、把控进度,Claude code负责干活;Fable 拒答降级的时候,直接复制上下文丢给左边的GPT接住,无缝换人。
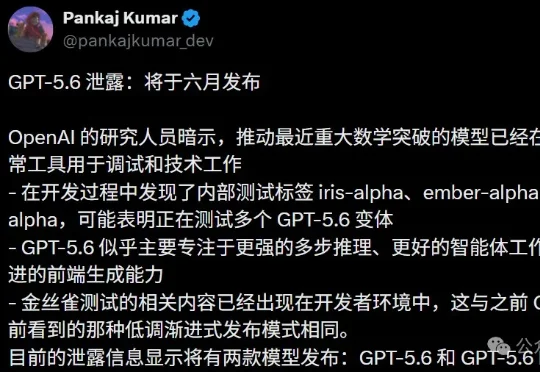
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。

在3D创作这个圈子,一直有个心照不宣的扎心真相: 那就是最难的一步从来不是生成,而是让模型变为可用资产。

发布24小时,神话级Claude 5光速登顶!不仅创下AI史上最大分差纪录,更将GPT-5.5直接斩落马下。

刚刚,Anthropic放出藏了俩月的大杀器——Claude Fable 5和Mythos 5,无异于扔下一枚炸弹。
不过,好用归好用,常规渠道订阅一个月大概需要 140 元,长期积累下来也是一笔不小的开销。最近我研究了不同的订阅途径,发现通过土耳其区进行订阅,费用大概能省下一半。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

当大学教育全面接入 AI 系统,接下来会发生什么?