
破纪录!OpenAI成为史上第一家估值万亿元的AI公司!独家融资协议:“别投对手公司”
破纪录!OpenAI成为史上第一家估值万亿元的AI公司!独家融资协议:“别投对手公司”一觉醒来,OpenAI新一轮融资终于盖棺论定——
来自主题: AI资讯
7068 点击 2024-10-04 19:43
 搜索
搜索
一觉醒来,OpenAI新一轮融资终于盖棺论定——

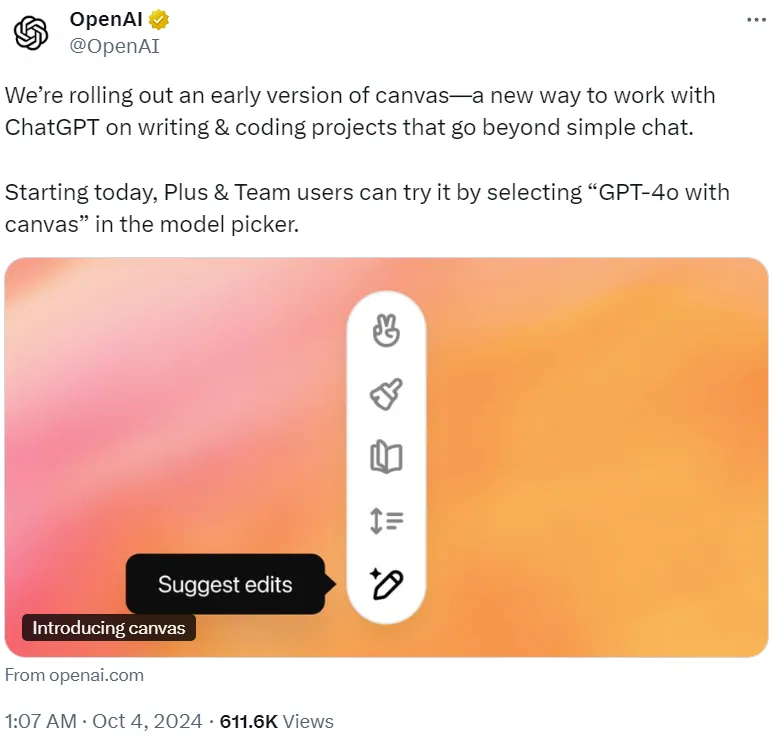
ChatGPT横空出世以来,首次迎来界面史诗级升级!全新canvas界面,开启了人类与AI协作研究、编码的新时代,更代表着终极AGI人机交互形态。

OpenAI的o1模型在通用语言任务上展现了显著的性能,最新测评展现了o1模型在医学领域的表现,主要关注理解、推理和多语言能力,结果大幅超越以往的模型!
OpenAI 刚刚融资,就迫不及待开始证明自己了。
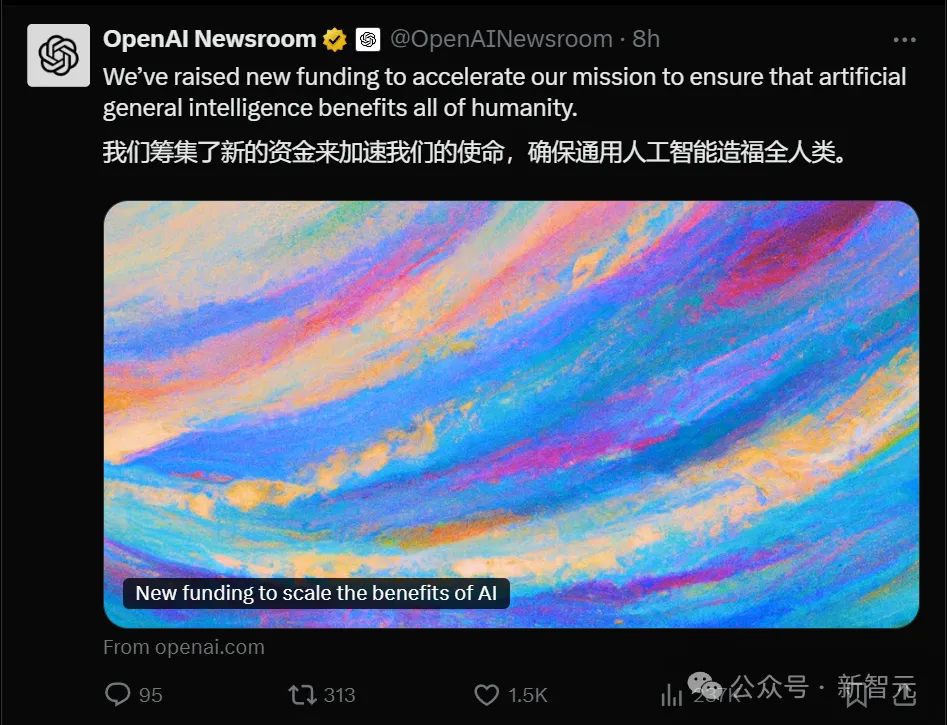
就在刚刚,OpenAI官宣:新一轮融资66亿美元(464亿人民币),估值已突破1570亿美元(超过1.1万亿人民币)!
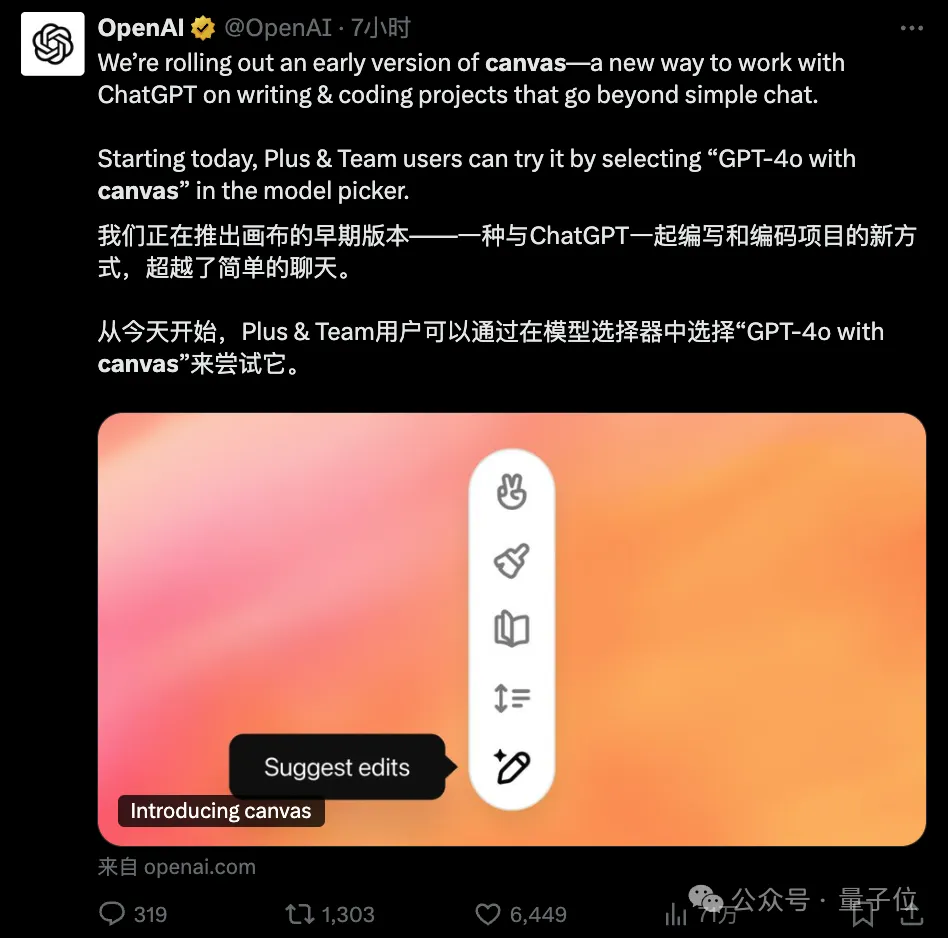
今天凌晨,OpenAI又有了一个大动作—— 发布Canvas,一个与ChatGPT合作写作和编程的新界面!

时隔两年,ChatGPT终迎来界面全新升级! 这一次,OpenAI官宣推出canvas。它不再是简单的对话框,而是能与ChatGPT「并肩作战」的全新界面。
今天可谓又是一个巨额融资日,OpenAI 在其官网上正式宣布完成了 66 亿美金的新一轮融资,估值为 1570 亿美金。OpenAI 说新资金将使他们能够加倍发挥在前沿 AI 研究方面的领导地位,提高计算能力,并继续构建帮助人们解决难题的工具。

OpenAI沸沸扬扬传了一个月的新融资轮终于尘埃落定。

十一假期第1天, OpenAI一年一度的开发者大会又来了惹!今年的开发者大会分成三部分分别在美国、英国、新加坡三个地点举办,刚刚结束的是第一场。