
第二代PPTAgent来了!中科院软件所开源首个本地通用幻灯片智能体,9B参数打平GPT-5
第二代PPTAgent来了!中科院软件所开源首个本地通用幻灯片智能体,9B参数打平GPT-5天下苦 PPT 久矣。
来自主题: AI技术研报
10883 点击 2026-03-19 10:22
 搜索
搜索
天下苦 PPT 久矣。
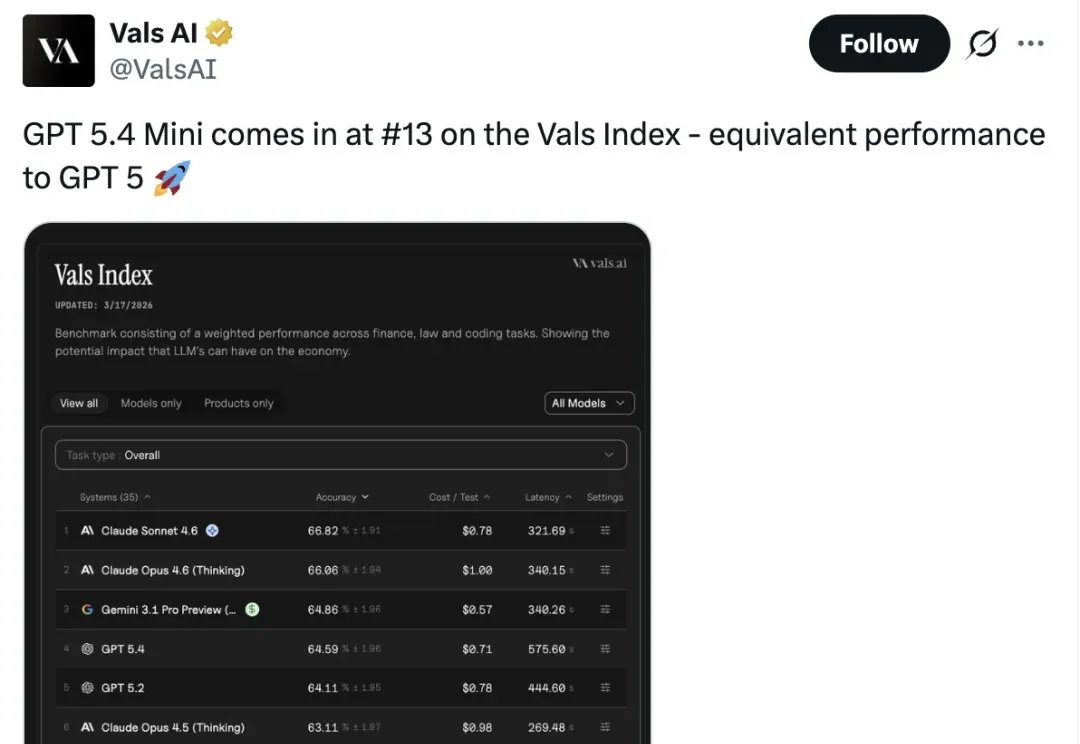
OpenAI刚推出的GPT-5.4 mini,Day0就已经被嫌弃了。

深夜,OpenAI祭出「双子星」GPT-5.4 mini和nano,实力逼近满血版,速度性价比拉满,用来编码、当「龙虾」主力真香!

GPT-5.4破纪录了!
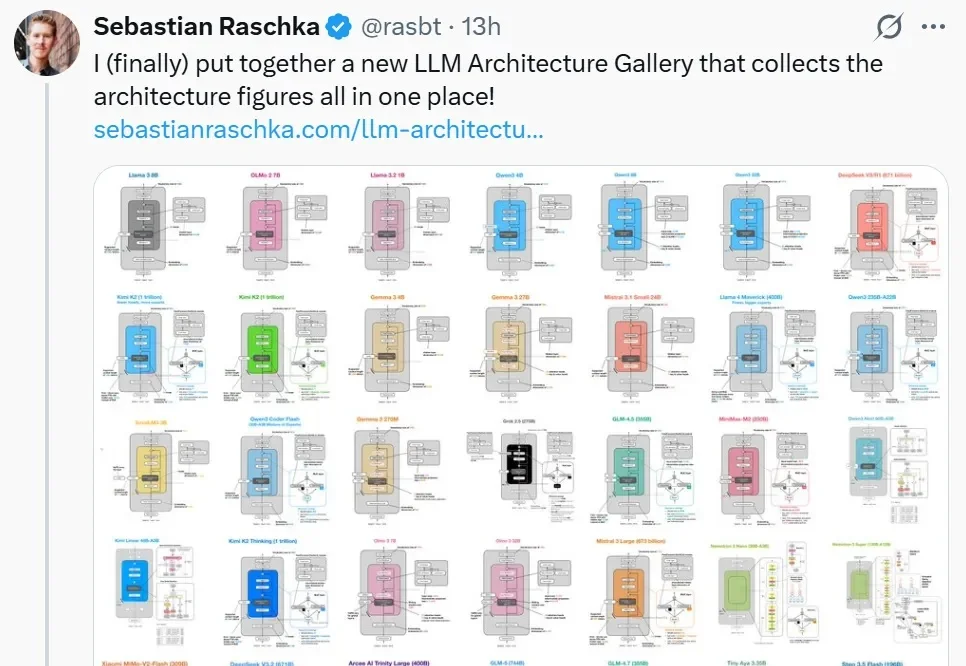
最近几年,大模型赛道好不热闹。

朋友们,你们是不是也这样: 遇到问题,打开ChatGPT,噼里啪啦打一堆提示词,它给你生成一段代码、一个方案,然后呢?

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。

上周带大家 0.83 拿下了 GPT Team,后台好多人问我,这个会员能不能变成 API 来用。答案是可以的,而且玩法比你想的多得多。今天这篇就手把手教你怎么搞定,全程跟着做就行,不需要什么技术基础。
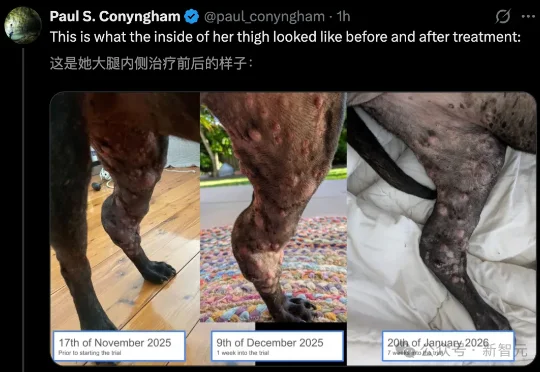
全网震撼!0生物学背景,澳洲大神为救回患癌爱犬,竟用ChatGPT+AlphaFold,设计出全球首支定制mRNA疫苗。短短数周,肿瘤缩小50%。这预示着,AI正加速攻克癌症的终极圣杯。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。