
持续怒斩53K星!狠人揭秘Clawdbot反行业记忆系统!跟ChatGPT大不同:不靠狂塞上下文,而是一个个md文件!网友:AI记忆第一次被工程化了
持续怒斩53K星!狠人揭秘Clawdbot反行业记忆系统!跟ChatGPT大不同:不靠狂塞上下文,而是一个个md文件!网友:AI记忆第一次被工程化了过去一年,几乎所有 AI 产品都在谈一个词:记忆。
来自主题: AI技术研报
7807 点击 2026-01-27 16:52
 搜索
搜索
过去一年,几乎所有 AI 产品都在谈一个词:记忆。
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。

这是一份迟到三年的行业复盘。牛津大学最新的实证研究撕开了那层遮羞布:2022年全球科技大裁员爆发时,ChatGPT甚至尚未发布。周期性缩编被伪装成技术性迭代,AI替资本背了三年的锅,直到今天真相才被彻底复位。

过去一整年,具身智能成了 AI 行业里最被反复提及、却最难真正落地的方向。一边是人形机器人发布会密集登场,另一边却始终缺乏可规模部署的现实成果。算法在进步,算力在堆叠,但问题始终没有改变:机器人到底该如何被教会在真实世界中行动。
进入到 2026 年,OpenAI 在关注消费级产品(如 ChatGPT、社交应用)之外,开始将一部分重心转向企业级市场。
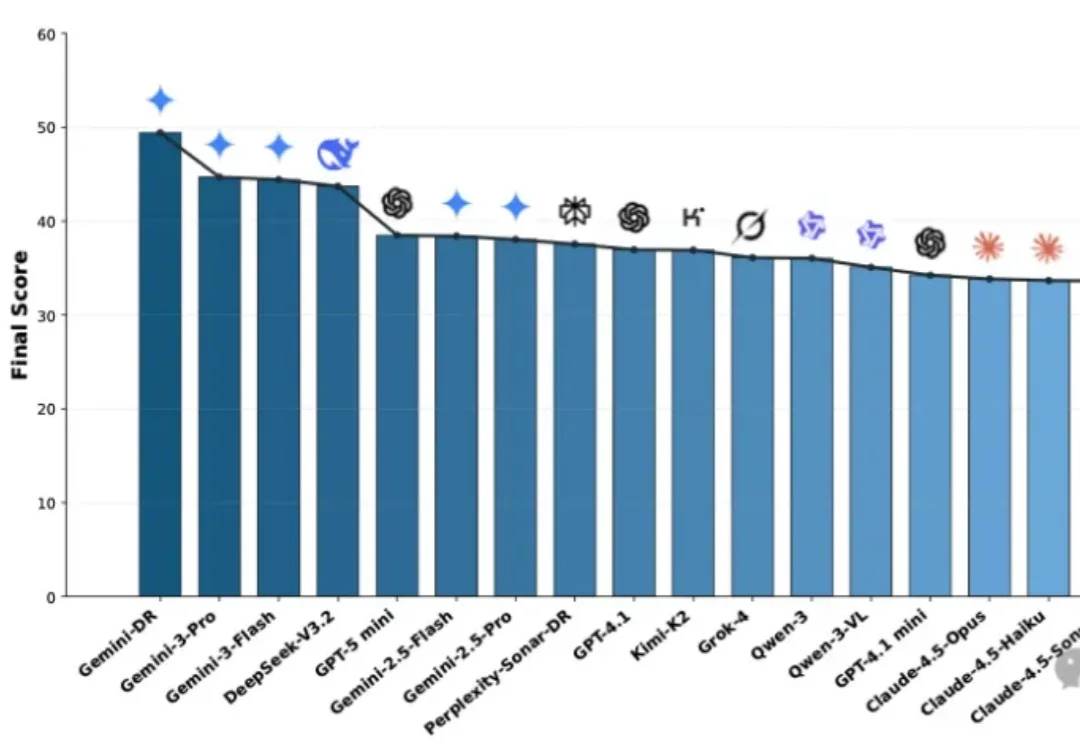
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。
一句神秘指令刷屏全网!ChatGPT启用全新「记忆」功能,画出了和人类相处的真相。如今,GPT-5.3已经在路上。

最近,移动应用数据分析商 Sensor Tower 发布了一份《State of Mobile 2026》。AI 应用的增长不但没有减速,反而更快了。AI 应用的下载量翻倍,达到 38 亿次;IAP 收入增长超过三倍,突破 50 亿美元;
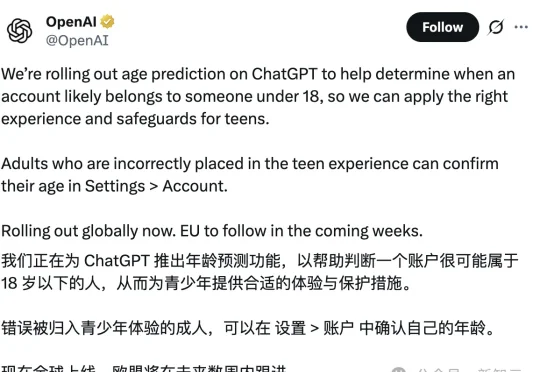
ChatGPT也推出「防沉迷系统」了?如果你习惯用缩写、语气太嫩,或者仅仅是作息不规律,都可能被判定为未成年!想恢复成人权限,代价是上传你的脸部3D扫描数据。不需要等到未来,欢迎来到2026年的「行为算命」时代。

OpenAI 收购 Torch Health 这件事,这两天我看到很多解读,基本都落在两个方向。一个是人才收购,四个人的小团队,买回去做 ChatGPT Health 的一块拼图。另一个是医疗布局,OpenAI 终于开始认真做垂直行业了。