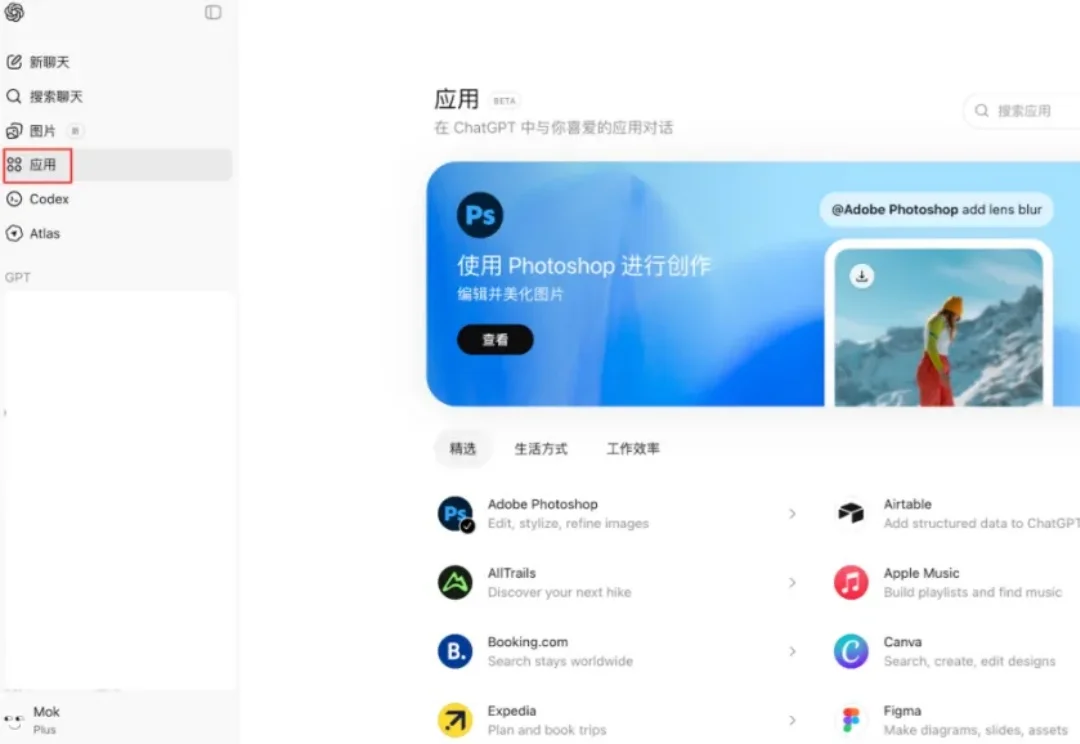
突发|ChatGPT 版应用商店正式上线
突发|ChatGPT 版应用商店正式上线就在刚刚,ChatGPT 应用商店已经正式推出。
来自主题: AI资讯
11328 点击 2025-12-18 16:56
 搜索
搜索
就在刚刚,ChatGPT 应用商店已经正式推出。

如果你还在纠结—— “学生用 AI 写作业算不算作弊?” “学校要不要禁 ChatGPT?”
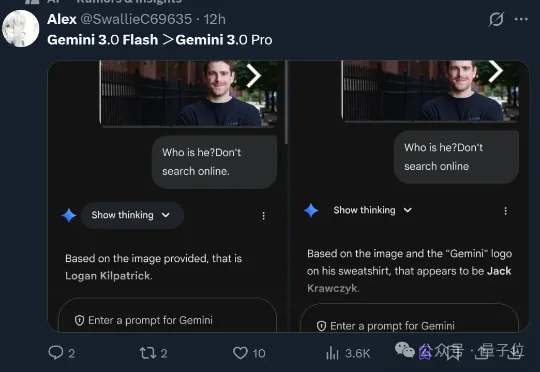
谷歌丢出Gemini 3 Flash,给AI圈示范了啥叫:小孩子才做选择题,成年人当然是全都要(doge)。一个公式来形容这款新模型:Gemini 3 Flash=Pro级智能+Flash级速度+更低价格。

如果你刚刚打开 X 并且正好关注了 OpenAI 和山姆・奥特曼,那么你可能会看到这样的照片:
不仅要抢好莱坞女演员的饭碗,AI 现在还要取代 P 站演员的工作。
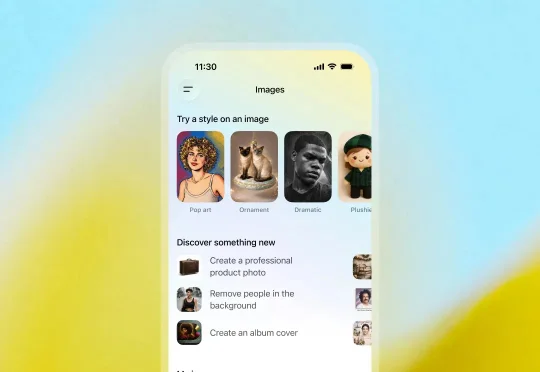
为了抢回头把交椅,OpenAI 今天正式推出了最新图像视觉模型 GPT-Image-1.5。这也是继 GPT-5.2 之后,OpenAI 红色警报计划中又一记重拳。

通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?
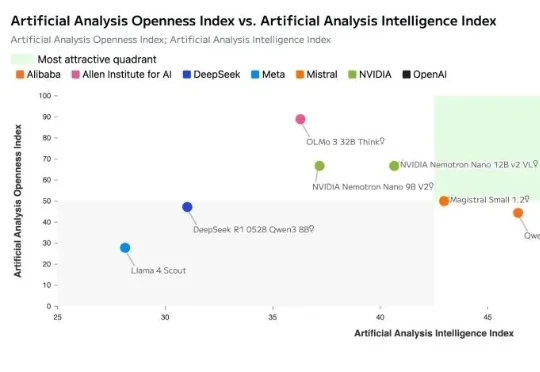
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。

ChatGPT 号称是最有情商、越聊越懂你的 AI,但是,你有没有想过,它是怎么记住你的。昨天刷 X 的时候,我看到一个帖子。一个叫 Manthan Gupta 的开发者,做了一件挺疯狂的事。他花了好几天时间,通过对话实验逆向破解了 ChatGPT 的记忆系统。

AI一分钟,人类十年功! 一觉醒来,AI推理模型已横扫特许金融分析师CFA考试。在一级考试中,Gemini 3.0 Pro创下97.6%的历史最高纪录。二级考试中,GPT-5以94.3%的成绩领先。