
北大字节开源首个时空推理视频模型!思考过程全透明,性能超越GPT-4o
北大字节开源首个时空推理视频模型!思考过程全透明,性能超越GPT-4oAI看视频也能划重点了!
来自主题: AI技术研报
11916 点击 2025-11-06 09:40
 搜索
搜索
AI看视频也能划重点了!

陶哲轩让ChatGPT把复杂的数学论文翻译成Lean代码,与AI合作完成形式化证明。AI能理解论文、写出正确命题,却常在关键处卡壳。经过人机配合,终于生成1125行被验证的证明。

如今,一位软件工程师 Teja Kusireddy 用数据扯开了这场“繁荣”背后的部分真相。他对 200 家 AI 公司进行了逆向工程、反编译代码,并追踪 API 调用,发现许多号称“颠覆性创新”的公司,其核心功能仍依赖第三方服务,只是在外层多套了一层“创新”的壳。市场宣传与实际情况之间的差距令人震惊。
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?
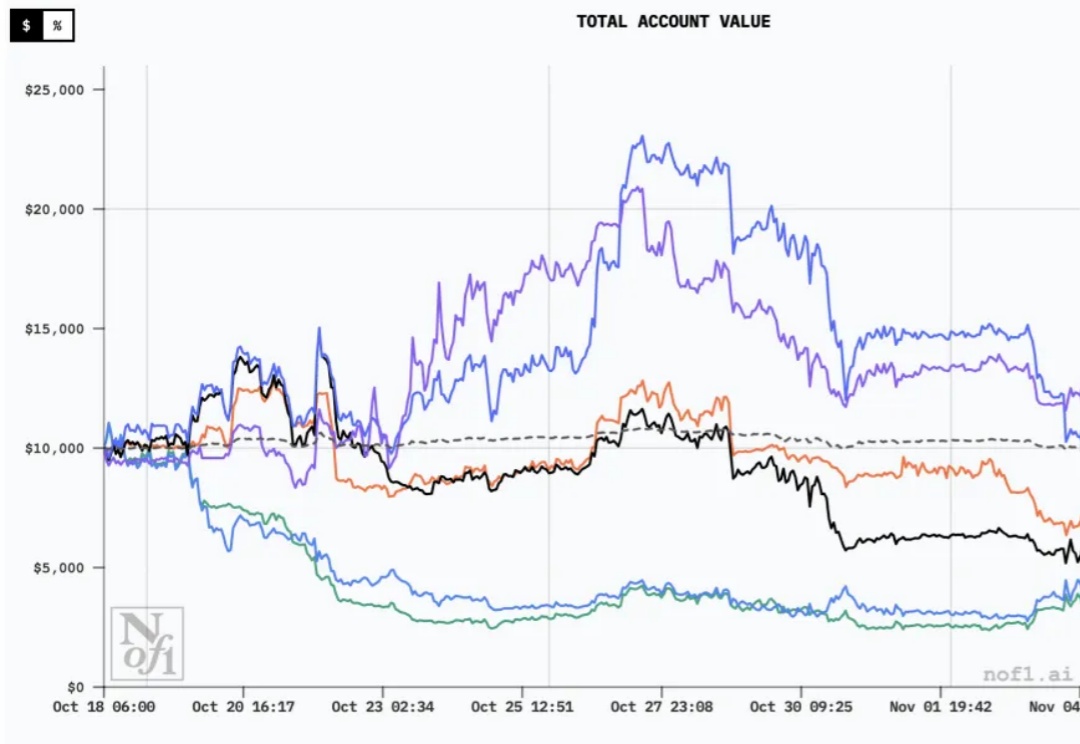
刚刚,为期两周的 AI 投资大乱斗收官。
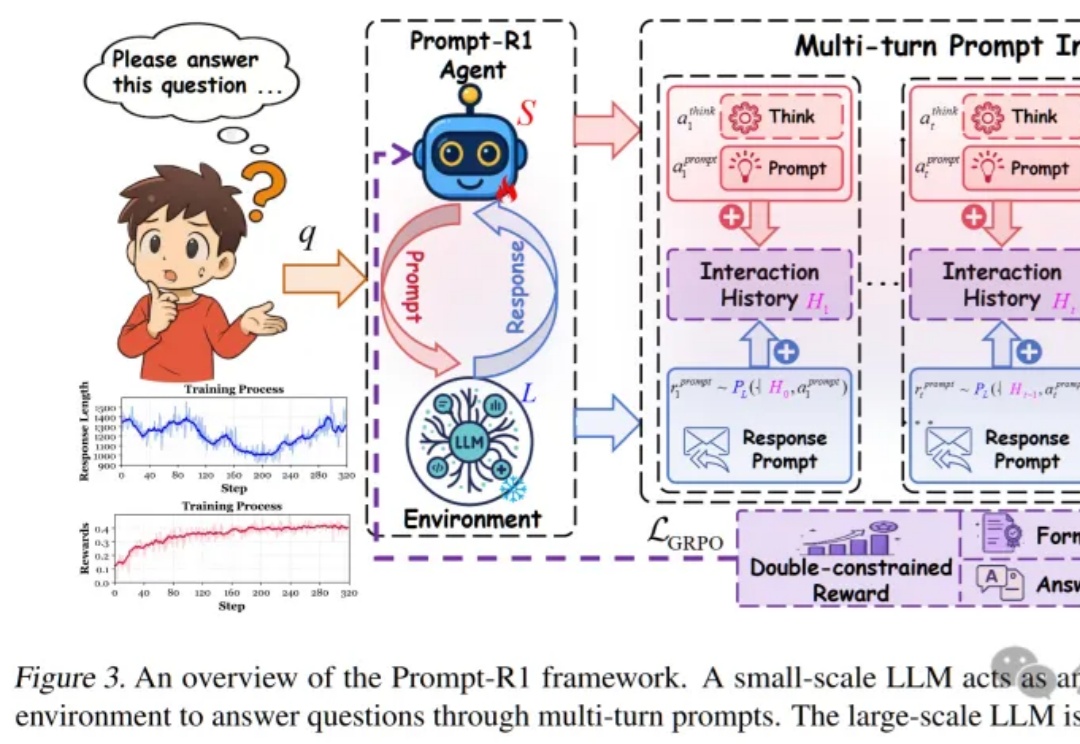
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。

传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。

当你发现自己刷到的视频、帖子是「AI制造」时,当身边的人用一种「AI腔调」和你说话时,你是不是想要迅速滑走,或者直接拉黑?加州大学伯克利分校等机构的权威研究证实,AI正在改变我们的说话、写作等交流方式,让我们的交际「塑料感」十足。

过去一周,我把主流 AI 浏览器都体验了个遍。 OpenAI 的 Atlas、Perplexity 的 Comet、Browser Company 的 Dia,再加上 Edge Copilot,市面上最火的 AI 浏览器,各有各的亮点,也各有各的坑。浏览器的未来长啥样?这些产品给出了完全不同的答案。

硅谷巨头正秘密培养第一批「AI原生代」。地点却选在了大学!在亚马逊、OpenAI、Meta、英伟达等巨头的推动下,CSU想成为美国首个并且是最大的AI赋能大学!