
新型「验证码」诞生?这张图让 ChatGPT、Claude、Gemini 都翻了车
新型「验证码」诞生?这张图让 ChatGPT、Claude、Gemini 都翻了车人眼秒懂,AI抓瞎!网友用光学错觉玩坏大模型,全网百万人围观。
来自主题: AI资讯
7897 点击 2025-10-28 14:17
 搜索
搜索
人眼秒懂,AI抓瞎!网友用光学错觉玩坏大模型,全网百万人围观。

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?

OpenAI现在已经完全是互联网大厂的路数了。
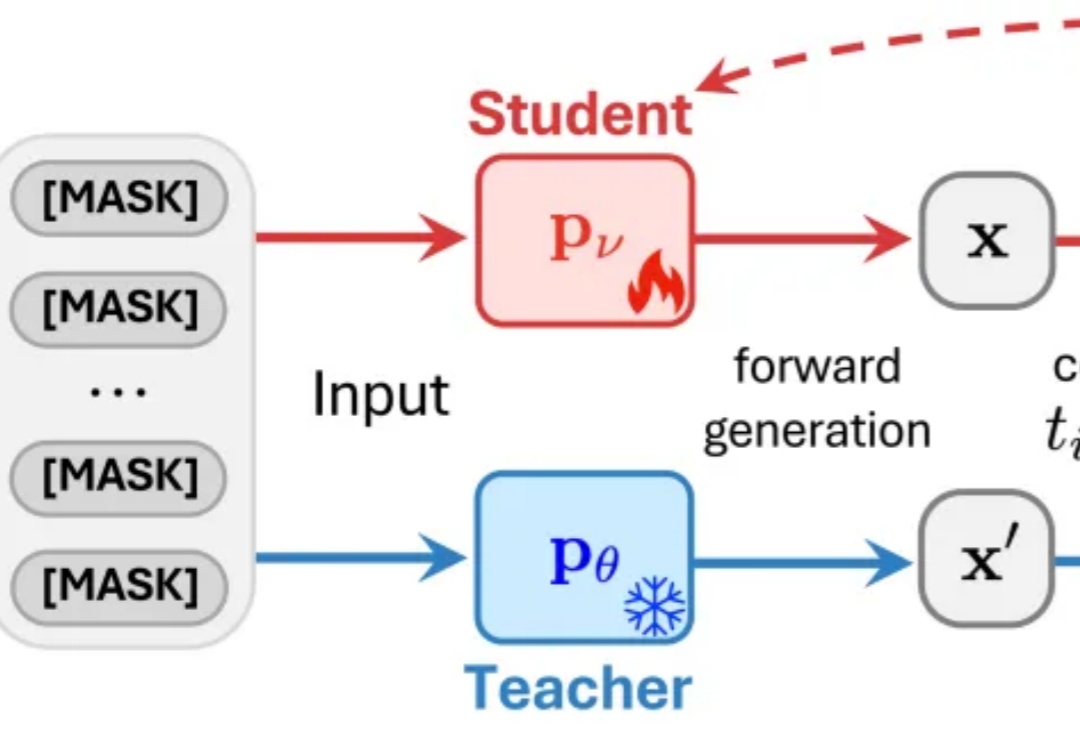
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

OpenAI凭ChatGPT坐拥8亿周活与预计约130亿美元年收入,订阅难覆盖成本、探索广告并豪赌算力扩张;Anthropic低调专攻企业,Claude在代码等场景见长,企业占营收八成、30万客户、年收入约70~90亿美元。OpenAI主攻C端,Anthropic深耕B端,前者求声量与规模,后者重价值与稳健,胜负未定。

近日,有开发者发现,OpenAI 官方在 “openai-agents-js” GitHub 仓库中被提及一个新模型:GPT-5.1 mini 。“显然 GPT-5.1 mini 是真实的……”以下是即将推出的 GPT 模型可能采用的命名规则。

OpenAI距离IPO更近一步。最新消息,软银批准了对OpenAI剩余的225亿美元投资,这笔融资的条件是OpenAI要在年底前完成重组,为上市铺平道路。与此同时,奥特曼各种骚操作被曝光:他绕过投行和律师,主要依靠自己的心腹和英伟达、AMD等谈判,操盘了价值1.5万亿美元的芯片交易。
我已经设置了不要给我发疑问句

在 AI 时代,开发的边界正被重新划定。 我们能够观察到,越来越多的产品经理、数据分析师、设计师,甚至内容创作者,正在熟练地使用 Cursor、ChatGPT、DeepSeek 等 AI 工具,解决真
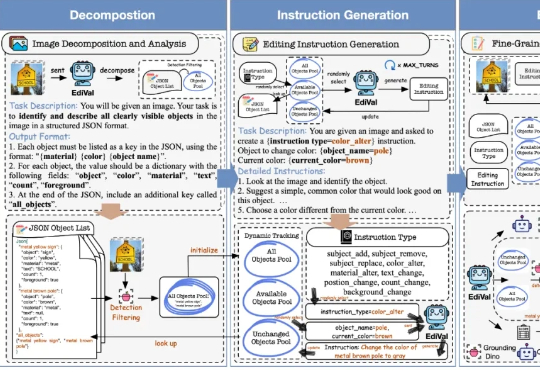
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?