马斯克Grok 4深夜大升级:200万逆天上下文、五倍GPT-5「脑容量」!
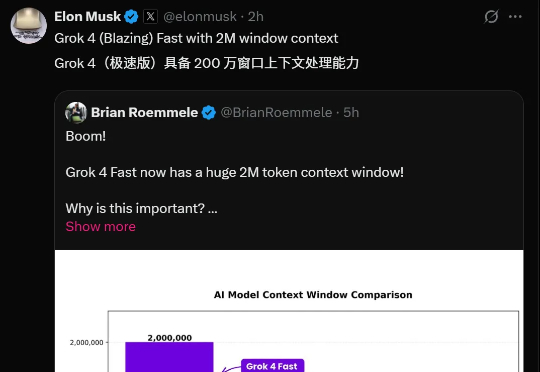
马斯克Grok 4深夜大升级:200万逆天上下文、五倍GPT-5「脑容量」!太快了!一天之内Grok连迎两大更新——Grok 4 Fast与Grok Imagine都进行了大升级。Grok 4 Fast把上下文窗口提高到2M,并把完成率拉到94.1%(推理)与97.9%(非推理)。这意味着,你不必再把一本书或一整个代码库切碎喂给模型,它可以一次吞下,然后稳定地给出结果。
来自主题: AI资讯
9620 点击 2025-11-09 15:42