

Anthropic指控中国大模型“使诈”,马斯克凶猛炮轰,海外网友贴脸开骂
Anthropic指控中国大模型“使诈”,马斯克凶猛炮轰,海外网友贴脸开骂今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。
来自主题: AI资讯
8327 点击 2026-02-24 18:59
今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。

刚刚, Anthropic 发推称,DeepSeek、Moonshot AI和MiniMax三家国内的 AI 公司对Claude进行大规模的蒸馏攻击。OK, A 社你真的很讨厌中国公司了。简单说就是:这三家公司用大量假账号,疯狂地向 Claude 提问,然后拿 Claude 的回答去训练自己的模型。
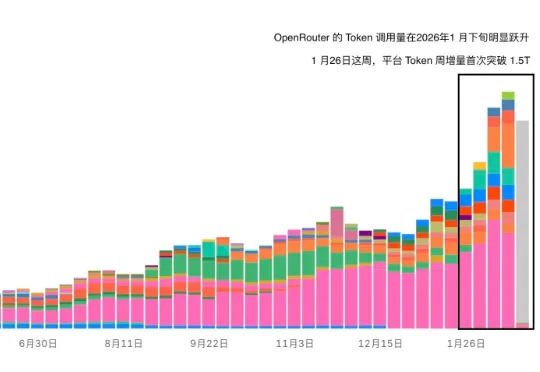
作为目前全球最主要的大模型 API 聚合网关之一,OpenRouter 的 Token 调用量在 2026 年 1 月下旬出现了明显跃升。自 1 月 26 日当周开始,平台 Token 周增量首次突破 1.5T,这一幅度在过去的调用曲线中并不常见。时间点同样值得玩味——这一轮增长几乎与 OpenClaw 的迅速传播高度重合。人们开始发现,OpenClaw 简直就是 Token 碎纸机。

智谱的股价在尾盘直线拉升,单日涨幅达到惊人的 42.72%,总市值一举冲破 3200 亿港元大关;而同样刚刚上市仅仅 43 天的 MiniMax,同样录得超过 14%的涨幅,市值稳稳站上 3000 亿港元的台阶。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知
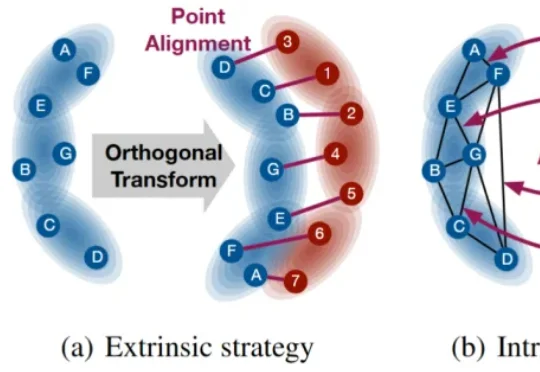
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
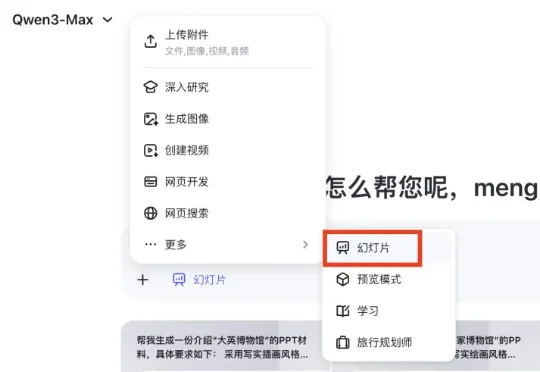
千问前脚刚把Qwen-Image-2.0甩出来,后脚就又放大招,冲着牛马党学生党的「痛处」下手了——就在这两天,重磅发布了AI PPT生成工具:Qwen AI Slides(幻灯片),据说从内容结构到视觉配图,一套全包……
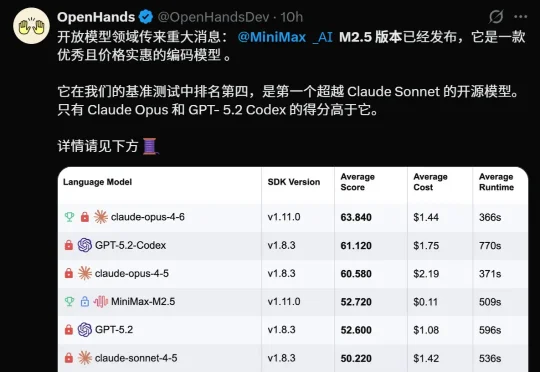
开源模型新王 MiniMax M2.5 震撼降临:M2.5 编码性能逼平 Claude Opus 4.6,价格却只有 1/20;1 美金 / 小时,这种尺寸和性能的模型,才能在算力短缺的时代不降智不卡顿,持续提供最好体验,成为最终王者!

随着 MiniMax M2.5 的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于 Agent RL 系统的一些思考。 在大规模、复杂的真实世界场景中跑 RL 时,始终面临一个核心难
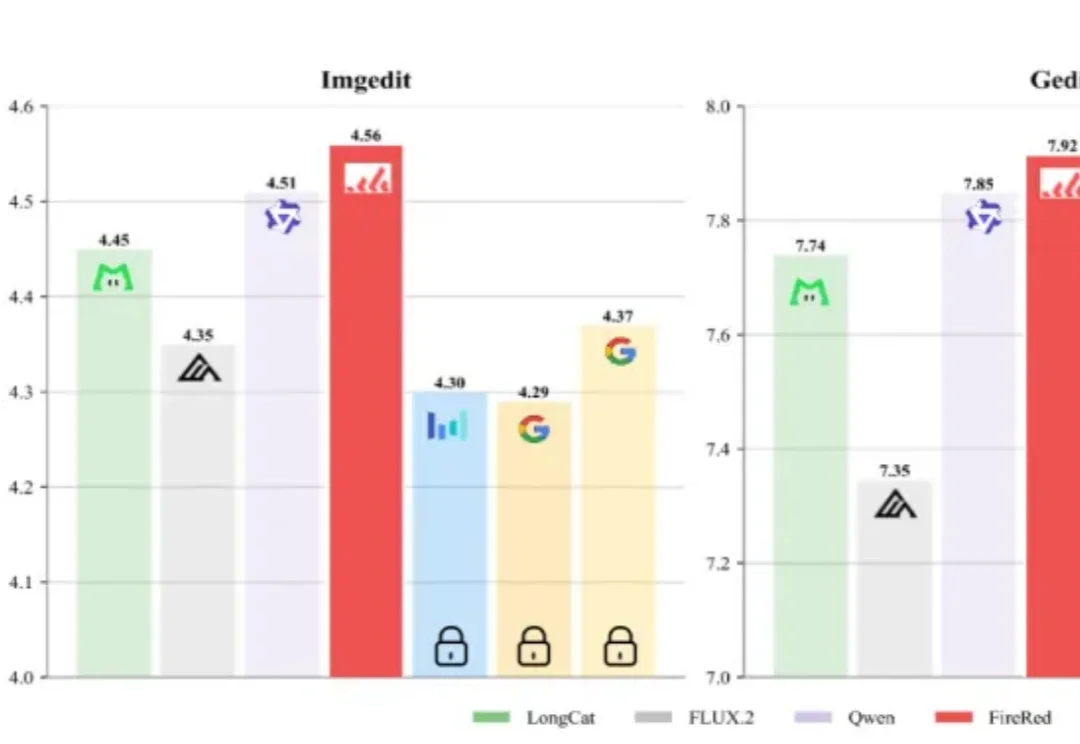
AI生图领域,又出了个“狠角色”。