
DeepSeek的MLA,任意大模型都能轻松迁移了
DeepSeek的MLA,任意大模型都能轻松迁移了DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
来自主题: AI技术研报
6187 点击 2025-03-07 10:24
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。

挤牙膏的新款 iPad Air 和 iPad 果然只是开胃小菜,今天苹果为我们带来了更有看点的 MacBook Air 和 Mac Studio 更新。

这项最新研究,由北京师范大学和南开大学的研究者们共同完成,于2025年发表于Internet Interventions 上,你只需要写一封信,写给自己,然后让ChatGPT 来给你一点反馈。不用约时间、也不用担心费用,只要在屏幕上敲下几行字,焦虑竟然真的能减少。

在启动 AIOS 之前,老罗最急迫的事情是融到下一笔钱。

GOSIM 是致力于为创新项目搭建全球化的开放、多元、包容的合作与发展平台。2025 年 5 月 6 - 7 日,GOSIM AI Paris 2025 大会将于在法国巴黎 Station F 举行,诚邀全球顶尖的 AI 专家、技术开发者、学者和开源创新者齐聚法国巴黎,共同探讨 AI 技术的未来发展。
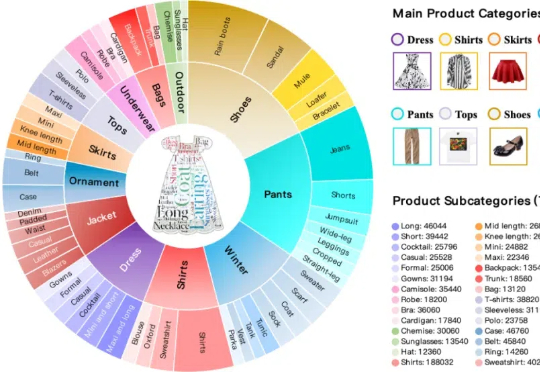
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
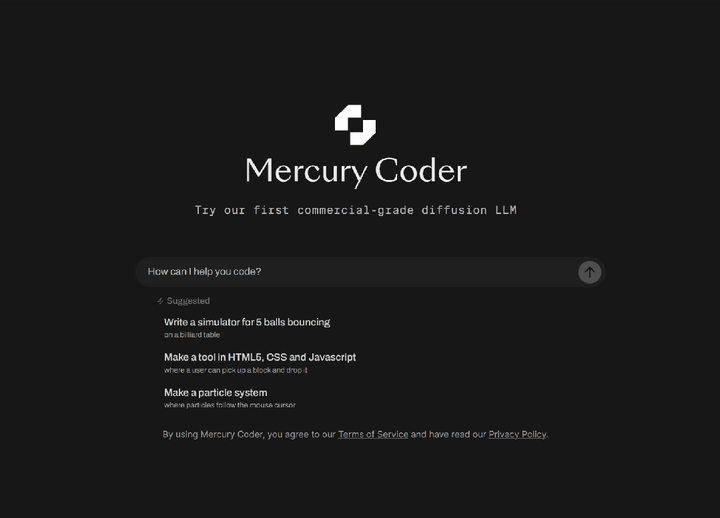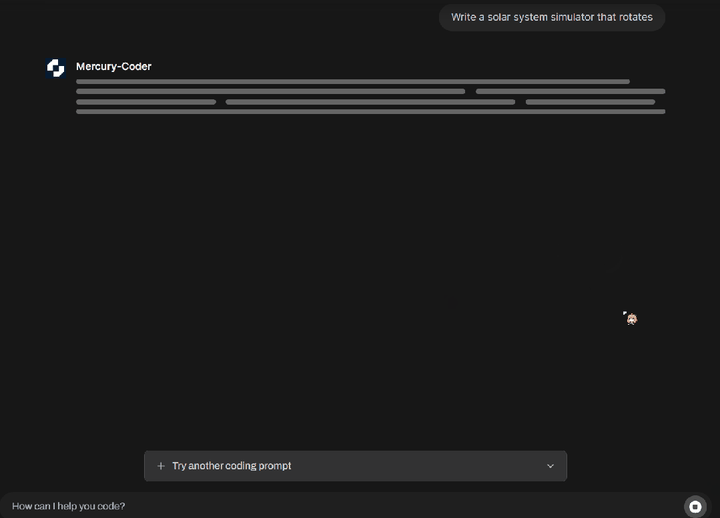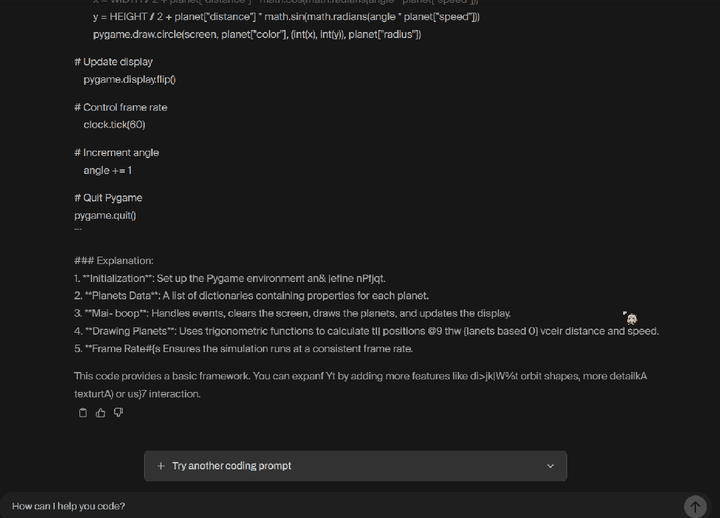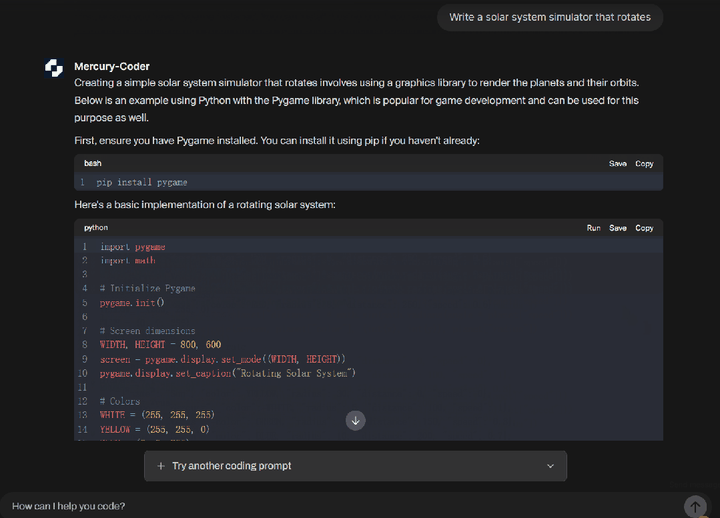
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。

智东西3月3日报道,继2月22日超过豆包后,今日,腾讯旗下AI大模型应用腾讯元宝超过DeepSeek,登顶iOS免费App榜。近期借势DeepSeek,腾讯元宝存在感爆棚,密集上新:2月17日宣布已上线DeepSeek-R1 671B和腾讯混元深度思考模型Thinker(T1);2月18日宣布调用腾讯元宝紧急支持微信搜索,让大家都能稳定体验和使用DeepSeek-R1;

现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。
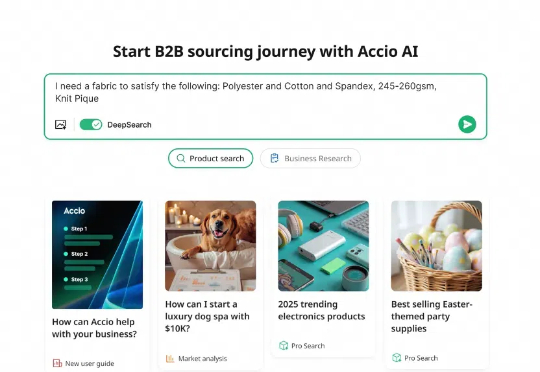
我想在沙漠里建一个室内滑雪场。DeepSeek:可以,详细计划如下。这是阿里国际站首个AI搜索引擎Accio接入DeepSeek之后的演示首秀。即便是这么离谱的想法,它还是在短短30秒内搜索了大量资料、反复推理,给出了一份有理有据的商业计划。