

免训练加速DiT!Meta提出自适应缓存新方法,视频生成快2.6倍
免训练加速DiT!Meta提出自适应缓存新方法,视频生成快2.6倍现在,视频生成模型无需训练即可加速了?! Meta提出了一种新方法AdaCache,能够加速DiT模型,而且是无需额外训练的那种(即插即用)。
来自主题: AI技术研报
4807 点击 2024-11-07 20:43
现在,视频生成模型无需训练即可加速了?! Meta提出了一种新方法AdaCache,能够加速DiT模型,而且是无需额外训练的那种(即插即用)。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。

拥有「五感」的机器人离我们不远了。
OpenAI 不仅专注于软件,还要深入硬件研究。

Meta 发布新闻稿,介绍了旗下 FAIR(基础人工智能研究)团队对于机器人触觉感知能力的研究情况,这项研究旨在让机器人通过触觉方式进一步理解和操作外界物体。

当地时间 10 月 30 日,Meta 发布第三季度未经审计财报。电话会上扎克伯格表示,Meta 计划在 2025 年继续增加对 AI 的投资,这“可能不是投资者短期内想听到的”。但他认为,潜在的回报是值得的。
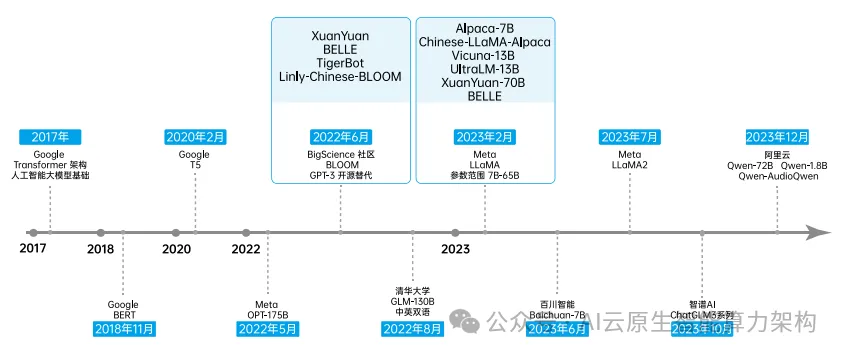
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。

AI 智能体可以设计 AI 吗?

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。

Agent-to-Sim (ATS) 是一个创新的三维模拟系统,能够从日常视频集合中学习三维代理的交互行为模型,由 Meta Codec Avatar 实验室主导研发。