
异议!顶流AI决战「逆转裁判」:o1险胜Gemini 2.5登顶、Llama 4零分垫底
异议!顶流AI决战「逆转裁判」:o1险胜Gemini 2.5登顶、Llama 4零分垫底悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。
来自主题: AI资讯
10946 点击 2025-04-18 10:37
 搜索
搜索
悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。

视频理解的CoT推理能力,怎么评?

满血版o3和o4-mini深夜登场,首次将图像推理融入思维链,还会自主调用工具,60秒内破解复杂难题。尤其是,o3以十倍o1算力刷新编程、数学、视觉推理SOTA,接近「天才水平」。此外,OpenAI还开源了编程神器Codex CLI,一夜爆火。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?
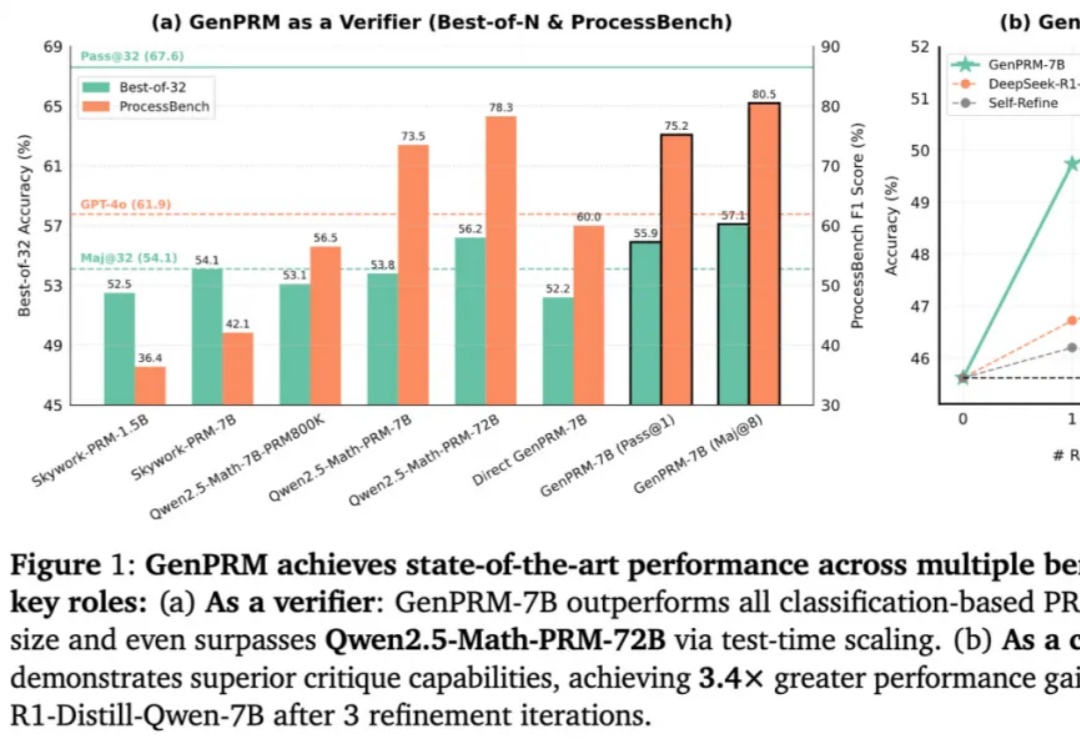
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。

Qwen 3还未发布,但已发布的Qwen系列含金量还在上升。2个月前,李飞飞团队基于Qwen2.5-32B-Instruct 模型,以不到50美元的成本训练出新模型 S1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果。如今,他们的视线再次投向了这个国产模型。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
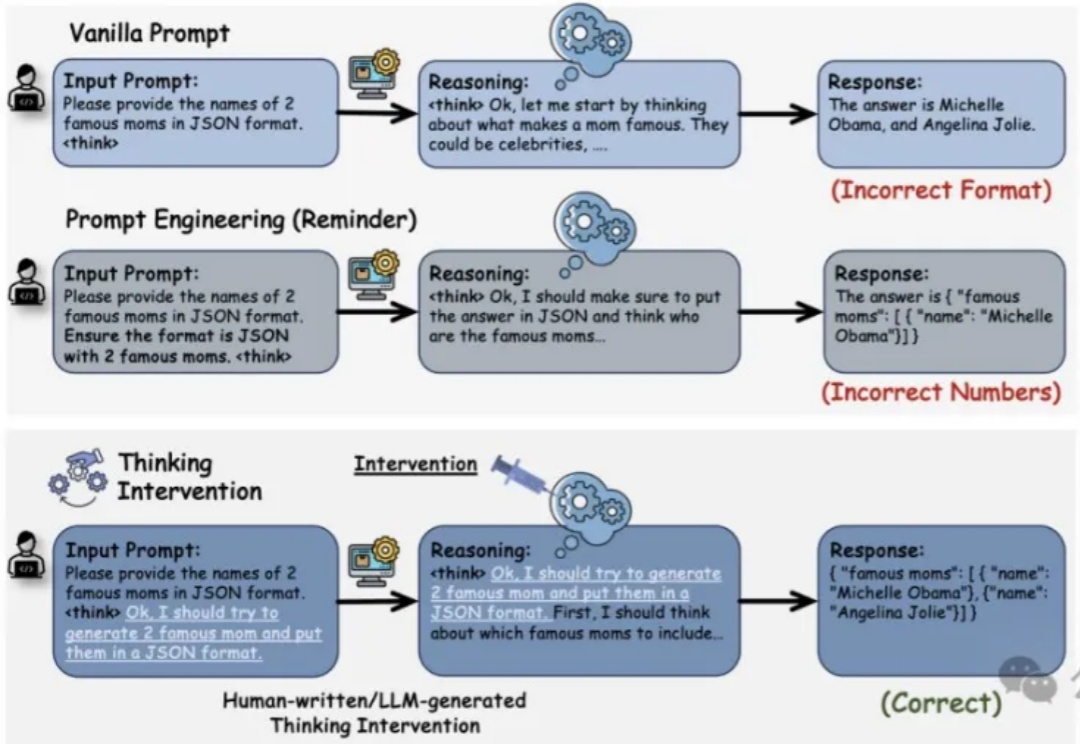
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
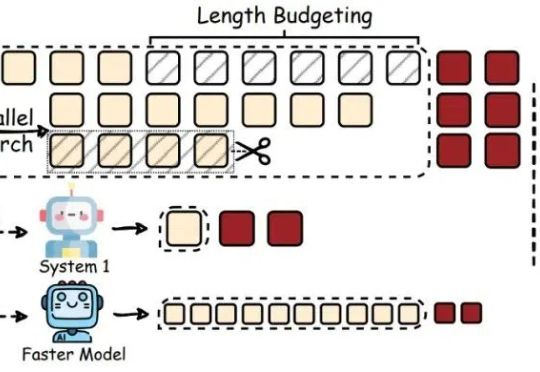
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。