
ChatGPT再进化:o1支持调用Python分析数据,网友:已经成为Copilot了
ChatGPT再进化:o1支持调用Python分析数据,网友:已经成为Copilot了今天一大早,ChatGPT突然更新——基于Python的数据分析功能,在o1和o3-mini当中也可以使用了。OpenAI介绍,现在可以通过两款模型调用Python,完成数据分析、可视化、基于场景的模拟等任务。
来自主题: AI资讯
10054 点击 2025-03-14 12:27
 搜索
搜索
今天一大早,ChatGPT突然更新——基于Python的数据分析功能,在o1和o3-mini当中也可以使用了。OpenAI介绍,现在可以通过两款模型调用Python,完成数据分析、可视化、基于场景的模拟等任务。

就在刚刚,谷歌Gemma 3来了,1B、4B、12B和27B四种参数,一块GPU/TPU就能跑!而Gemma 3仅以27B就击败了DeepSeek 671B模型,成为仅次于DeepSeek R1最优开源模型。

o3-mini成功挑战图论中专家级证明,还得到了陶哲轩盛赞。经过实测后,他总结称LLM并非是数学研究万能解法,其价值取决于问题得性质和调教AI的方式。
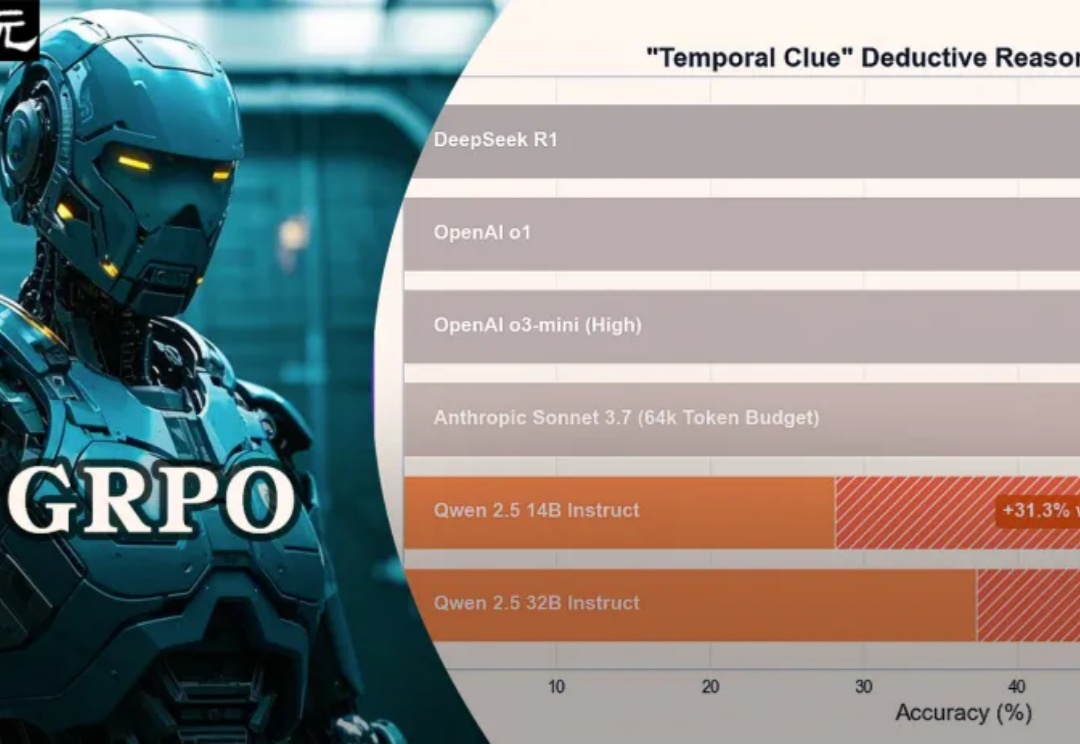
32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。

随着 AI 能力的提升,一个常见的话题便是基准不够用了——一个新出现的基准用不了多久时间就会饱和,比如 Replit CEO Amjad Masad 就预计 2023 年 10 月提出的编程基准 SWE-bench 将在 2027 年饱和。
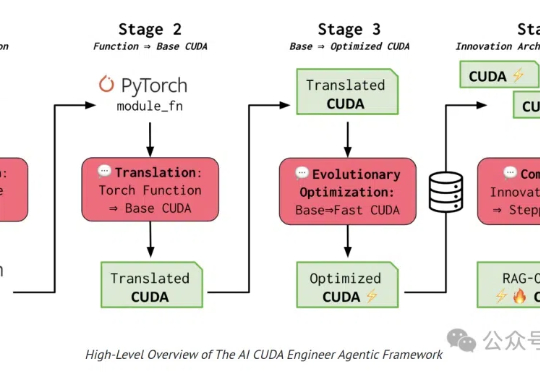
高调亮相的世界首个「AI CUDA工程师」,宣称能让模型训练速度飙升100倍,如今却上演了一场「作弊」闹剧。OpenAI研究员用o3-mini,11秒便发现了内核代码有bug!
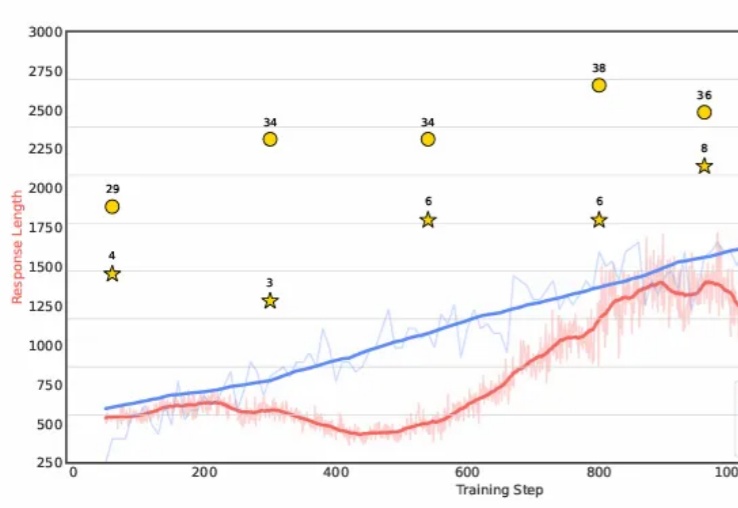
只刷逻辑益智题,竟能让 AI 数学竞赛水平大幅提升?

就在刚刚,Anthropic祭出首个混合推理Claude 3.7 Sonnet,堪称扩展思考模式的最强模型。在最新编码测试中,新模型暴击o3-mini、DeepSeek R1,AI编码王者出世了。
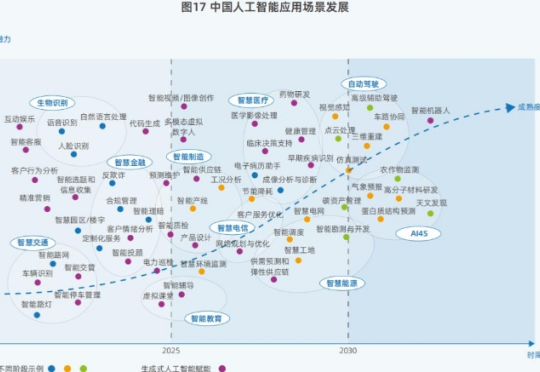
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。