
程序员从此不再写代码!红杉专访Codex团队,o3白菜价真相曝光
程序员从此不再写代码!红杉专访Codex团队,o3白菜价真相曝光红杉专访OpenAI Codex团队揭示AI编程的未来:从工具协作迈向「异步自主Agent」时代。Codex正从代码补全演化为可独立完成任务的智能体。此外还有更大爆料!
来自主题: AI资讯
8548 点击 2025-06-13 12:39
 搜索
搜索
红杉专访OpenAI Codex团队揭示AI编程的未来:从工具协作迈向「异步自主Agent」时代。Codex正从代码补全演化为可独立完成任务的智能体。此外还有更大爆料!
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
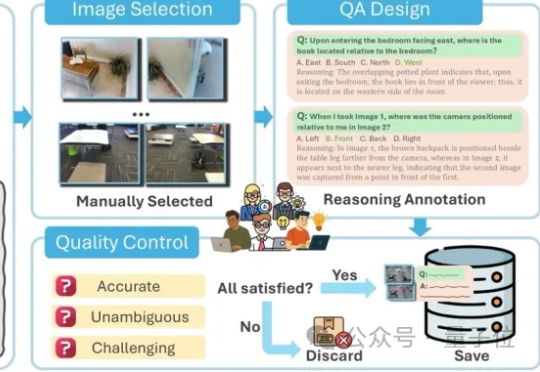
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗? 空间智能,正是大模型走向具身智能的关键拼图。
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。
OpenAI深夜放大招,正式推出“最新最强版”推理模型o3-pro! 而且同一时间,o3模型降价80%不降智。官方测评结果显示,在专家评估中,所有人一致更偏爱o3-pro而非o3的回答。
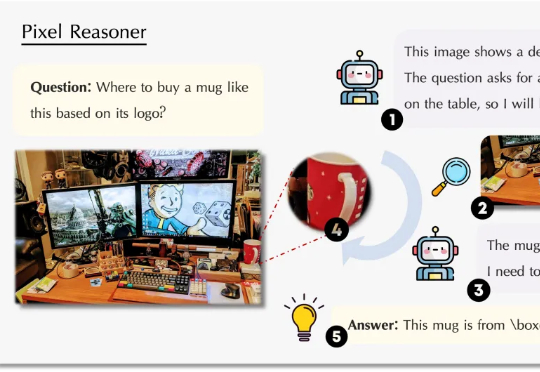
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。
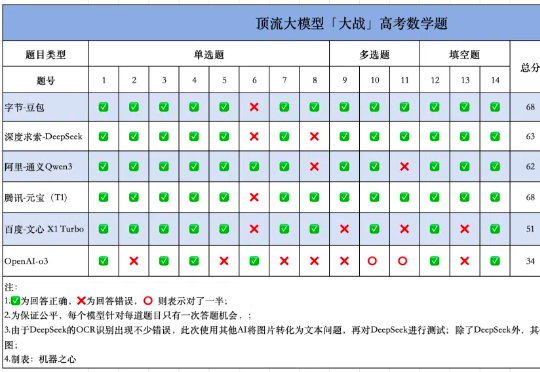
还在让大模型写高考作文?有本事做高考数学卷子。 又是一年高考时。 这届考生上午刚经历了抽象作文的洗礼,下午又被数学无情创飞。
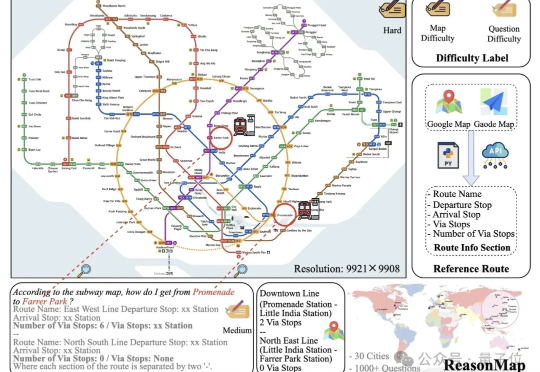
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
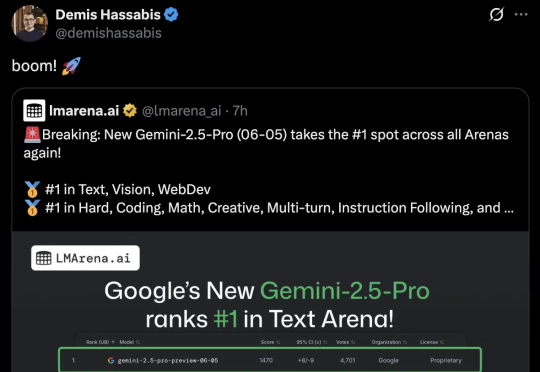
谷歌深夜携全新Gemini 2.5 Pro强势归来,仅用一个月碾压旧版Gemini 2.5。数学、编程、推理全面封神,稳坐所有榜单第一。