到底是谁会相信RAG已死啊?
到底是谁会相信RAG已死啊?最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
来自主题: AI技术研报
10210 点击 2026-06-01 09:27
 搜索
搜索
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的RAG(检索增强生成)方案依赖语义相似度检索历史信息,但“语义相似”并不等于“真正相关”,常常出现检索结果不完整、无法区分信息相关性、缺乏推理能力等问题。
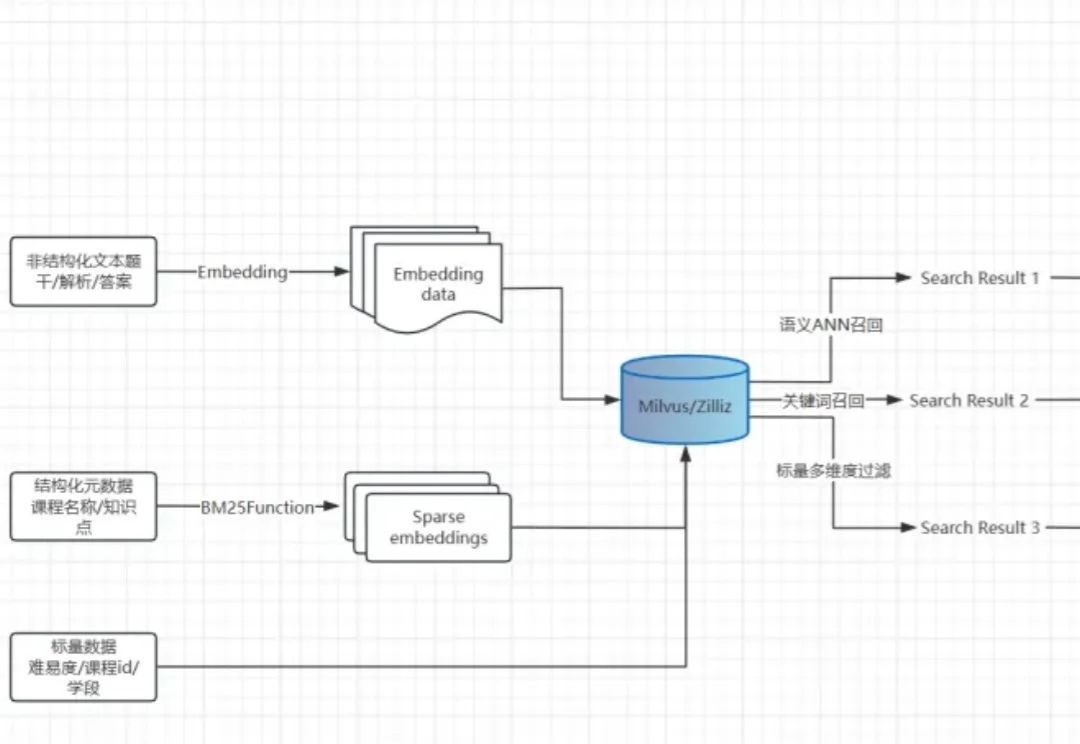
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
2022年10月,Elon Musk 以 440 亿美元收购 Twitter,第一件事就是解雇 CEO Parag Agrawal。这位被 Jack Dorsey 亲自提拔的印度裔工程师,在舆论场里几
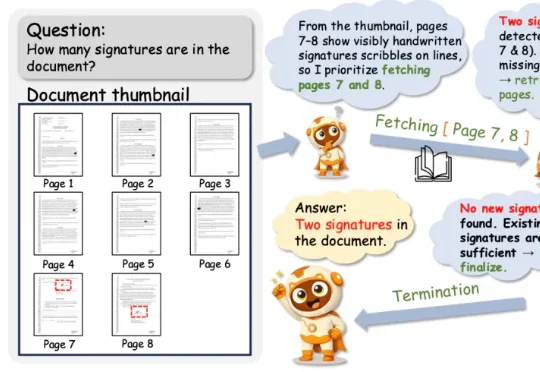
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。
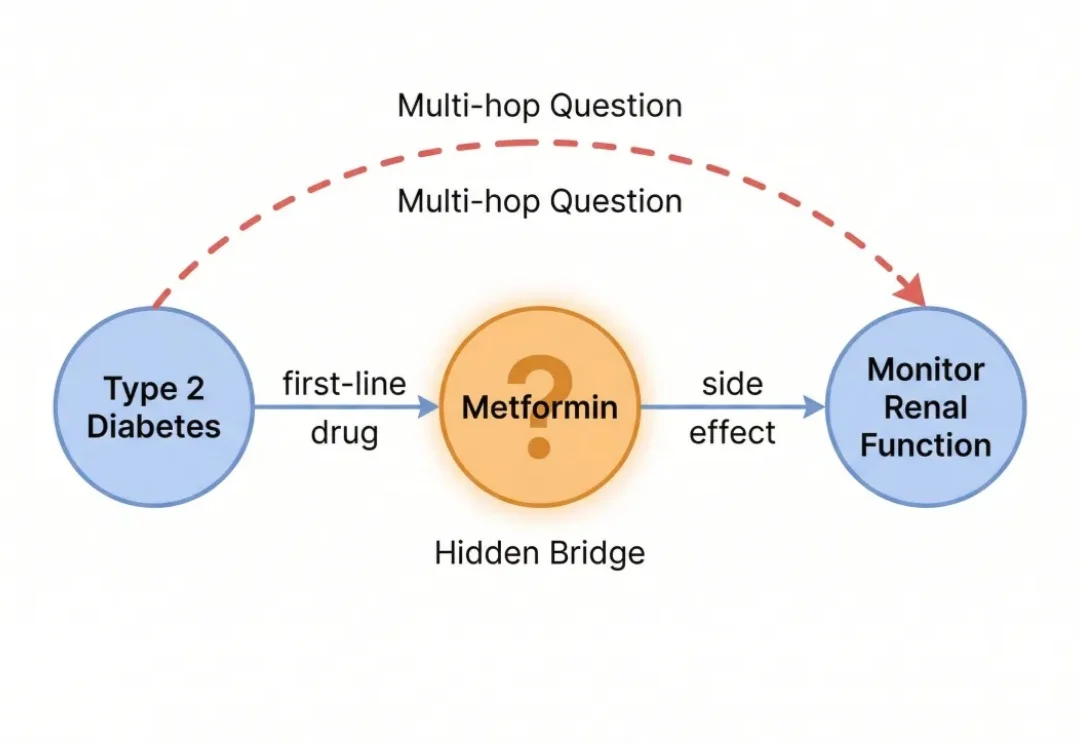
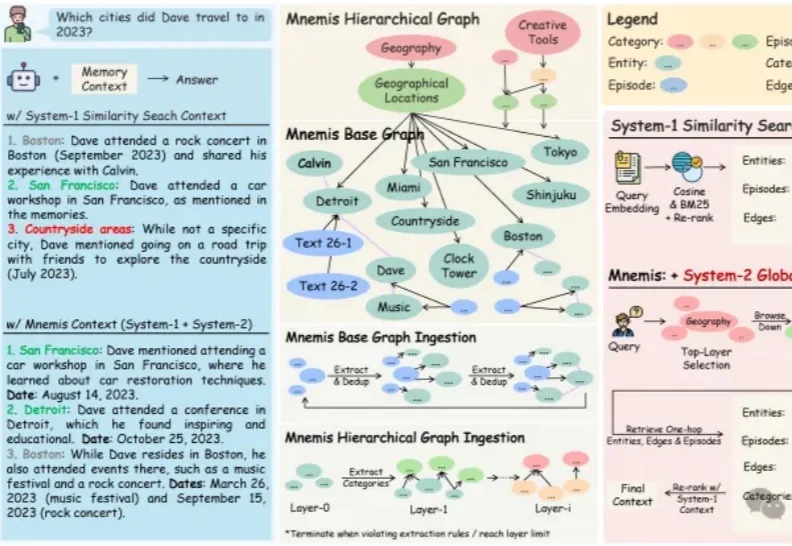
做 RAG 多跳问答的朋友,应该没有人还没被图数据库PUA 过。
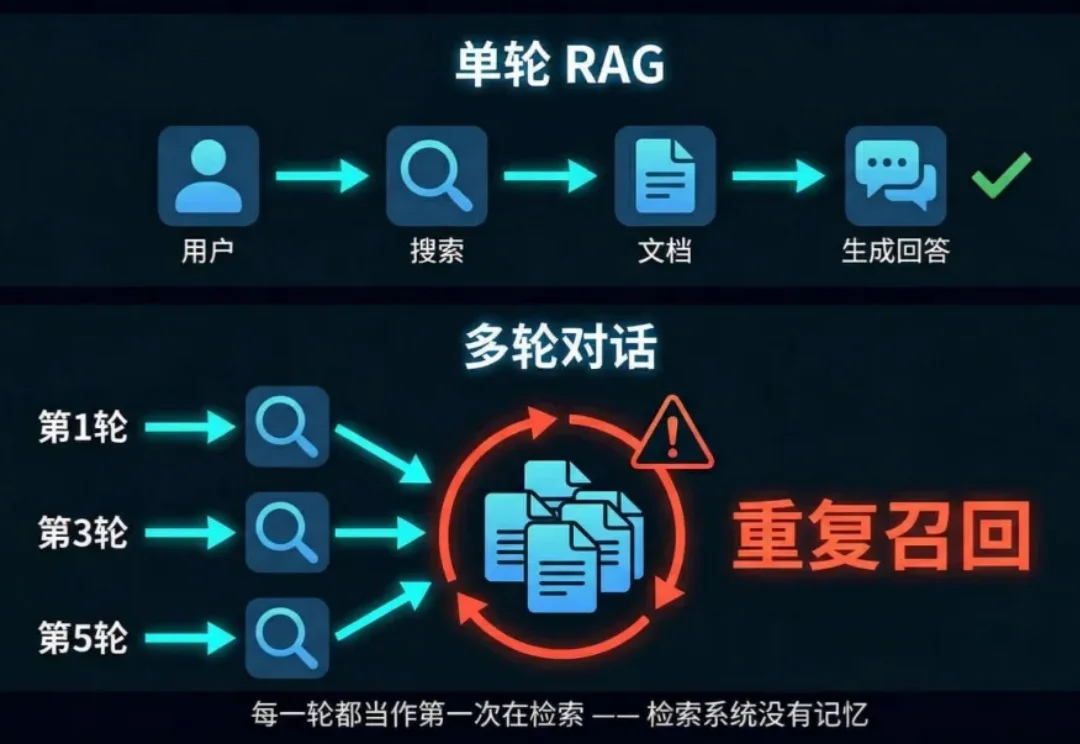
做 RAG 的团队,基本都会在多轮对话上吃过亏。
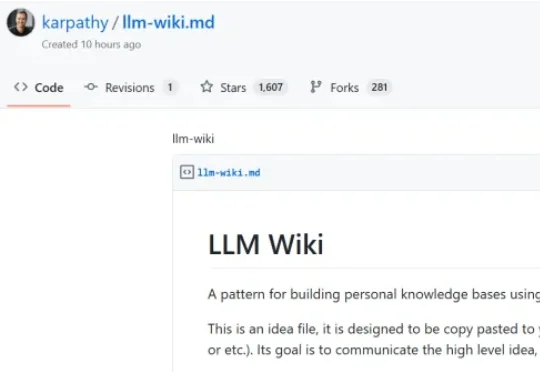
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。
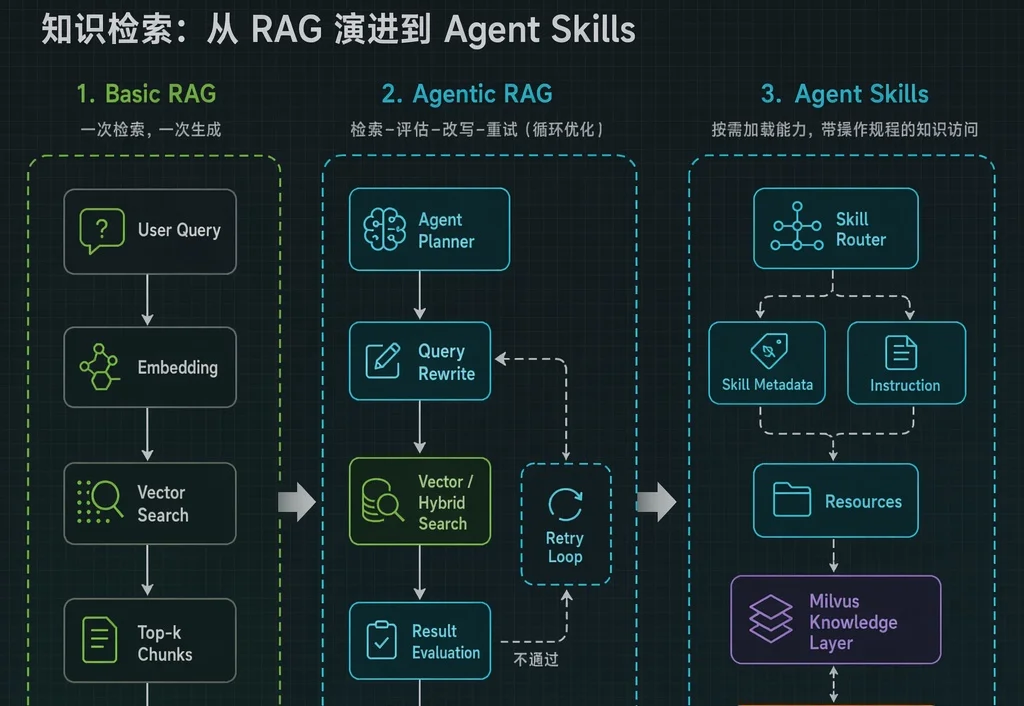
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。