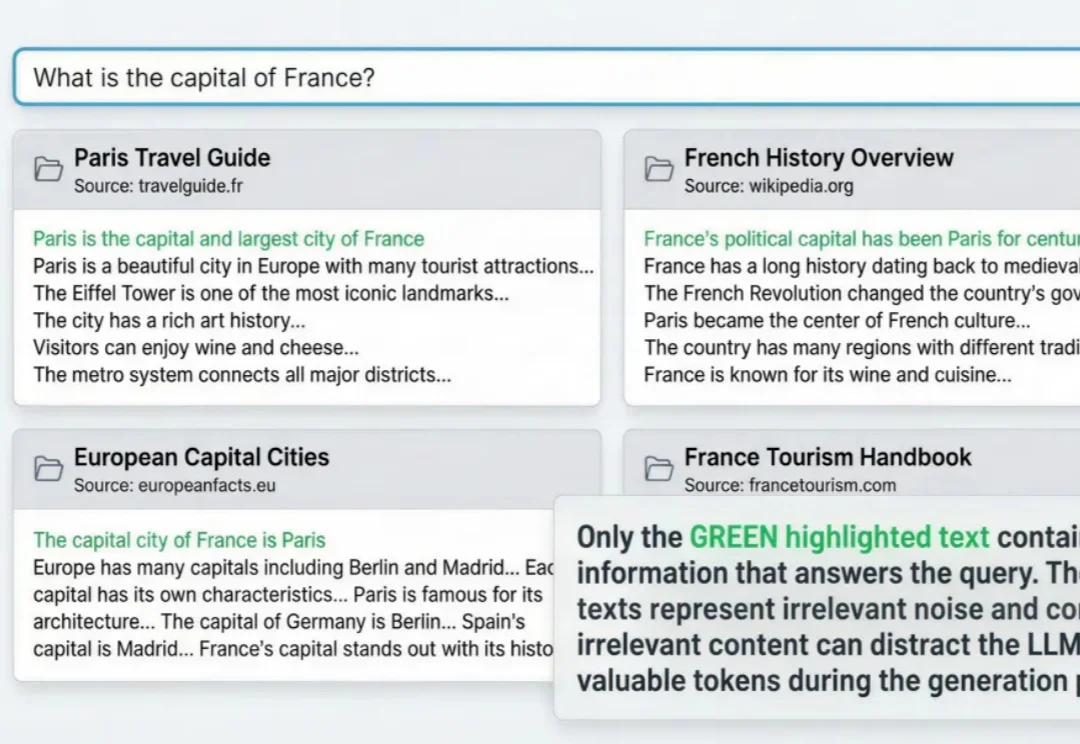
官宣,Milvus开源语义高亮模型:告别饱和检索,帮RAG、agent剪枝80%上下文
官宣,Milvus开源语义高亮模型:告别饱和检索,帮RAG、agent剪枝80%上下文RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
来自主题: AI技术研报
10416 点击 2026-01-15 09:19
 搜索
搜索
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。

企业级场景中,无论是做RAG还是agent,我们都会面临一个问题:出于数据隐私以及合规要求,数据必须保留在本地。但传统的本地存储方案往往存在数据隔离性差、崩溃易丢数据、配置管理混乱、操作不可撤销等问题。

2022年,Google Cloud 将π计算到100万亿位,在2025年,高性能计算界的知名评测机构 StorageReview只用了4个月的时间,花了不到一千美元电费就将π算到314万亿位,这可不是为了炫技,而是说明高性能计算也可以很节能。

最近一年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
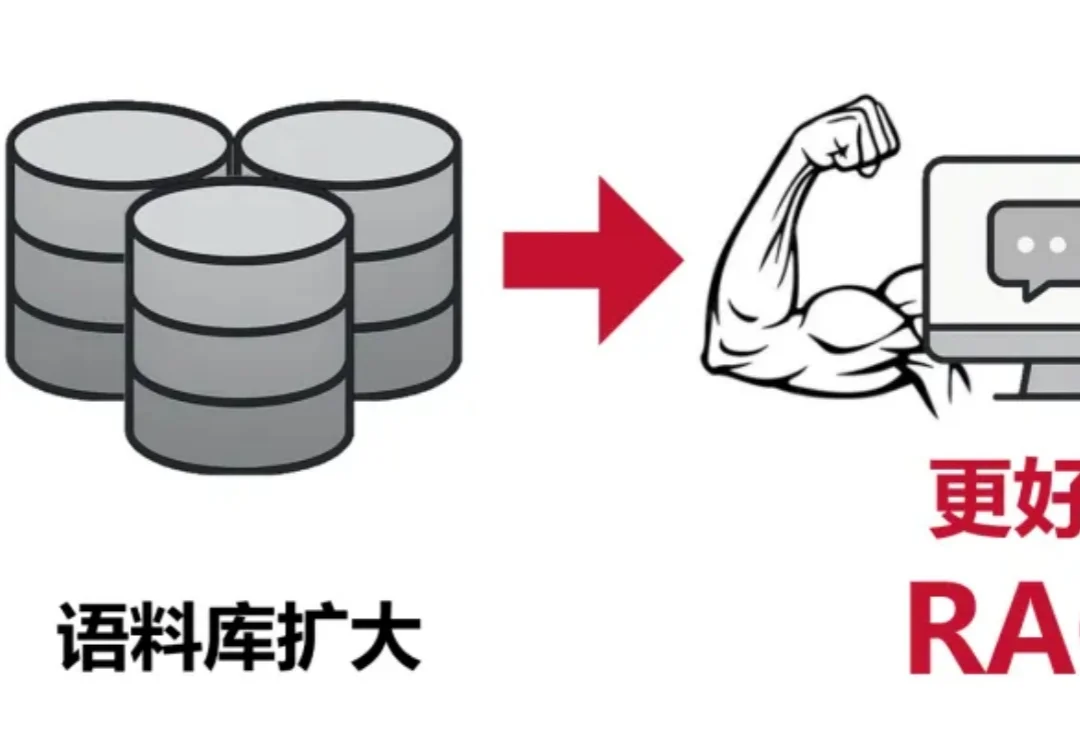
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。
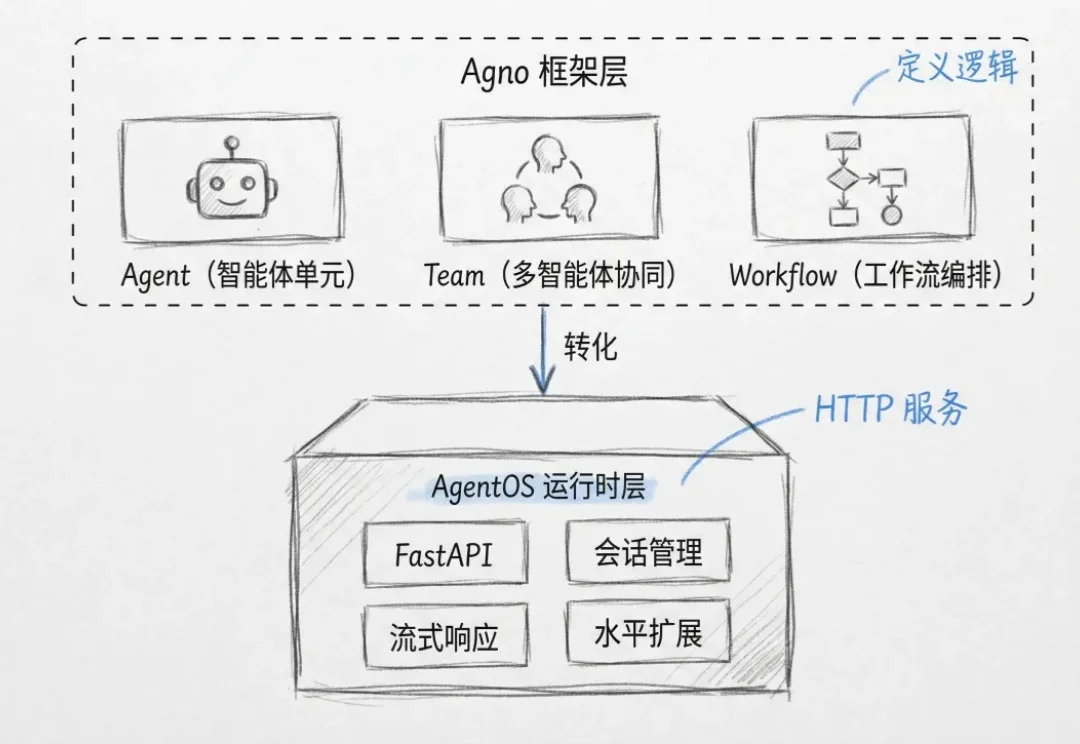
今天还是聊聊生产级agent怎么搭这回事。

最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。

近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期