一夜颠覆Sora神话,H200单卡5秒出片!全华人团队开源AI引爆视频圈
一夜颠覆Sora神话,H200单卡5秒出片!全华人团队开源AI引爆视频圈AI视频生成进入了秒生极速时代!UCSD等机构发布的FastWan系模型,在一张H200上,实现了5秒即生视频。稀疏蒸馏,让去噪时间大减,刷新SOTA。
来自主题: AI资讯
7895 点击 2025-08-07 17:55
 搜索
搜索
AI视频生成进入了秒生极速时代!UCSD等机构发布的FastWan系模型,在一张H200上,实现了5秒即生视频。稀疏蒸馏,让去噪时间大减,刷新SOTA。
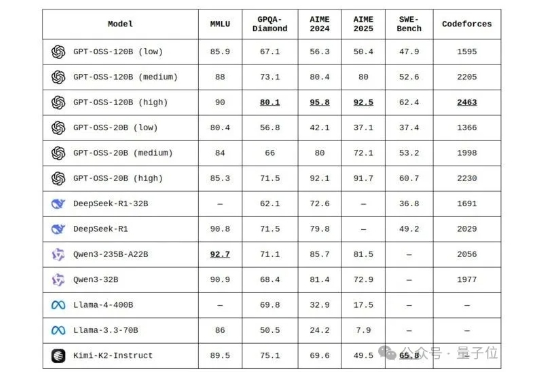
全网开扒GPT-oss,惊喜发现…… 奥特曼还是谦虚了,这性能岂止是o4-mini的水平,直接SOTA击穿一众开源模型。
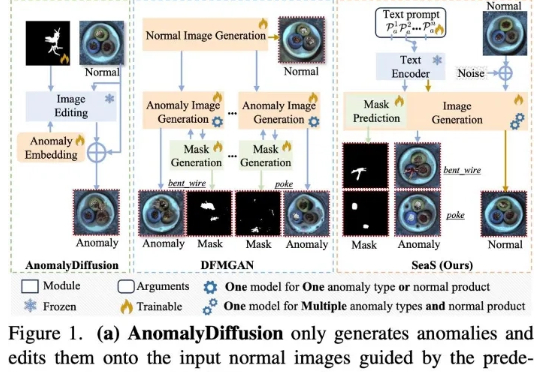
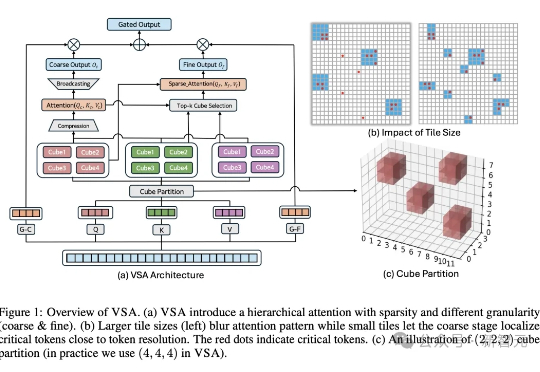
当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
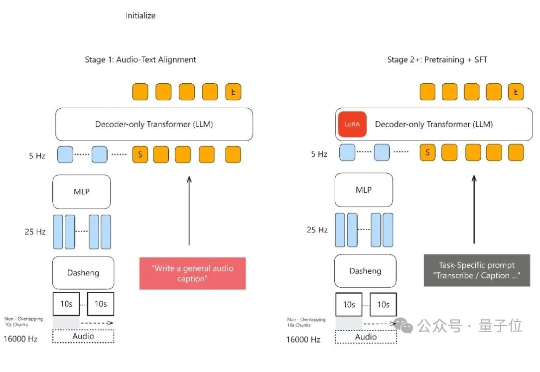
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
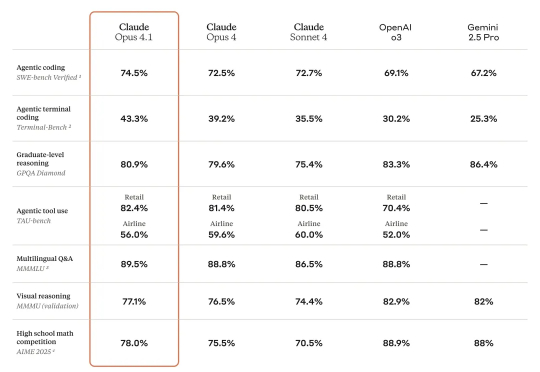
还是Claude痛快,Claude Opus 4.1前脚曝光,今天这就正式发了。编程性能再次突破天花板,超越Claude Opus 4,拿下SOTA。此外在Agent任务和推理方面进一步升级。但加量不加价,定价和Claude Opus 4一样。

通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。
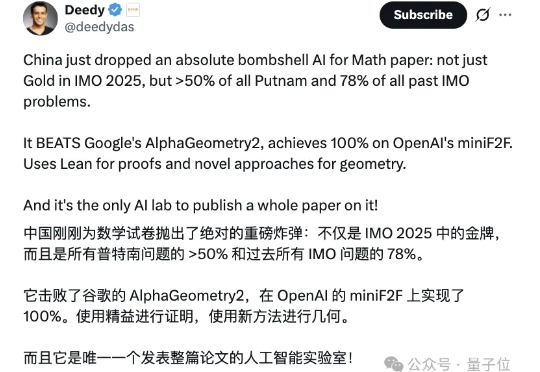
不仅能达IMO银牌水准,更能解决普特南数学竞赛难题,甚至超越顶尖模型o4-mini! 字节发布全新复杂数学解决模型——Seed-Prover。
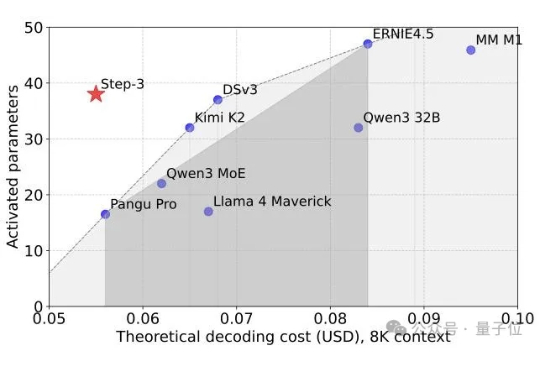
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。

WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
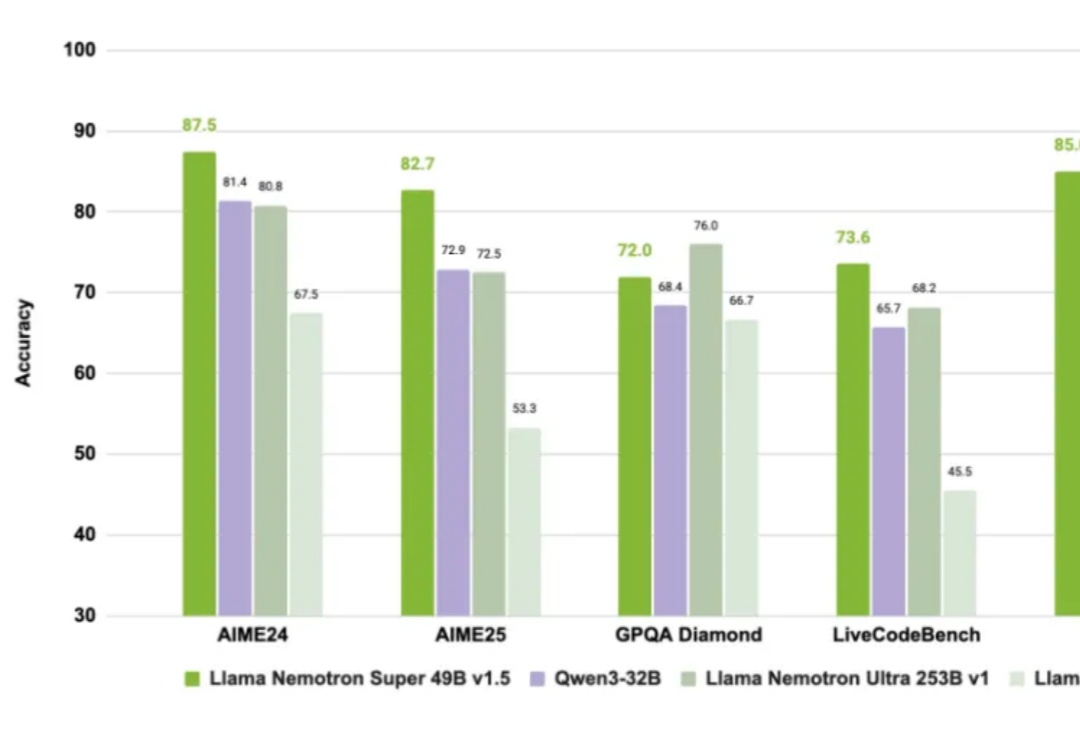
众所周知,老黄不仅卖铲子(GPU),还自己下场开矿(造模型)。