早于DeepSeek Engram!用「查表」重置Transformer记忆 | ICLR
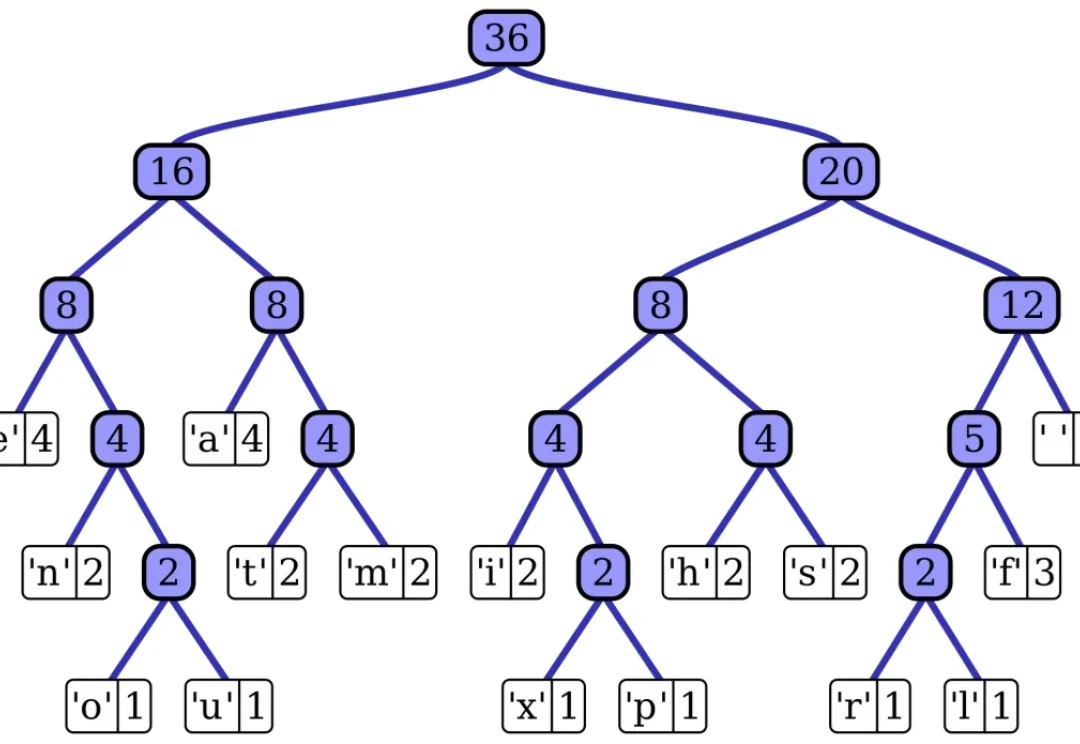
早于DeepSeek Engram!用「查表」重置Transformer记忆 | ICLRICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
来自主题: AI技术研报
8985 点击 2026-03-31 10:04