
豆包有Seed,火山有种
豆包有Seed,火山有种结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。
来自主题: AI资讯
11199 点击 2026-02-15 21:53
 搜索
搜索
结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
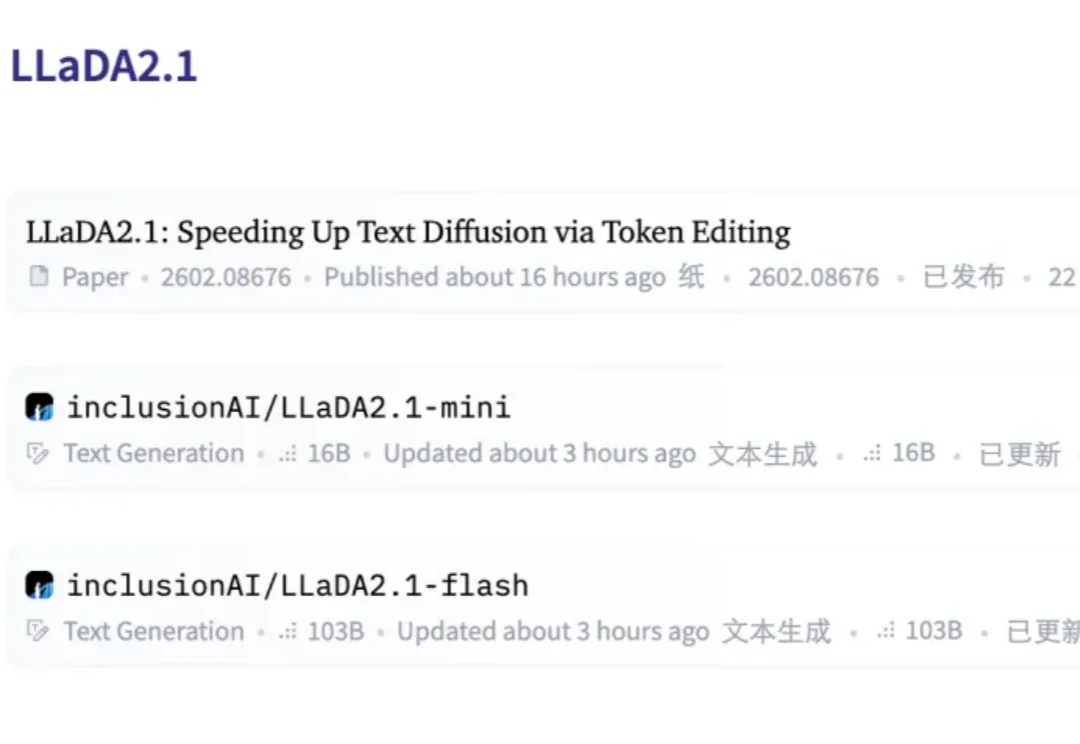
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!

在2026年的世界经济论坛上,微软 CEO 萨提亚·纳德拉(Satya Nadella)与贝莱德 CEO 拉里·芬克(Larry Fink)进行了一场对话。
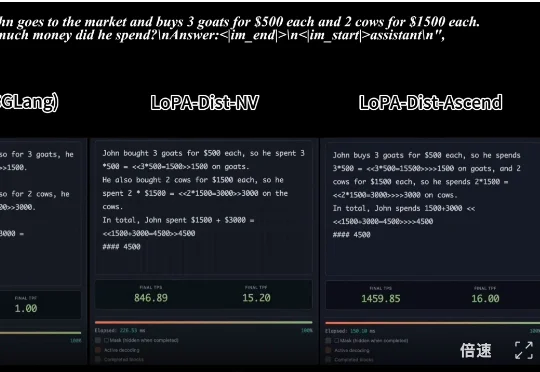
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台

今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。
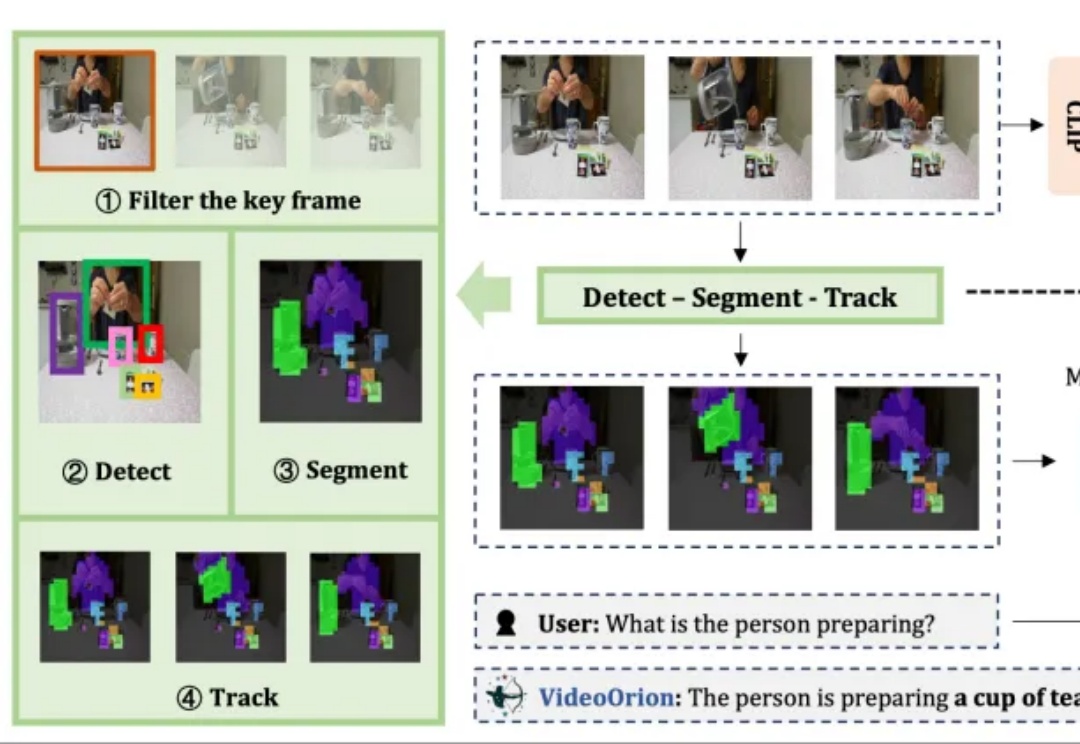
被顶会ICCV 2025以554高分接收的视频理解框架来了!

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%

魔幻啊魔幻。 全球顶级咨询公司麦肯锡,居然收到了OpenAI最近给Tokens消耗大客户颁发的奖牌。 麦肯锡自己还怪自豪的,第一时间就把奖牌po到了领英上。