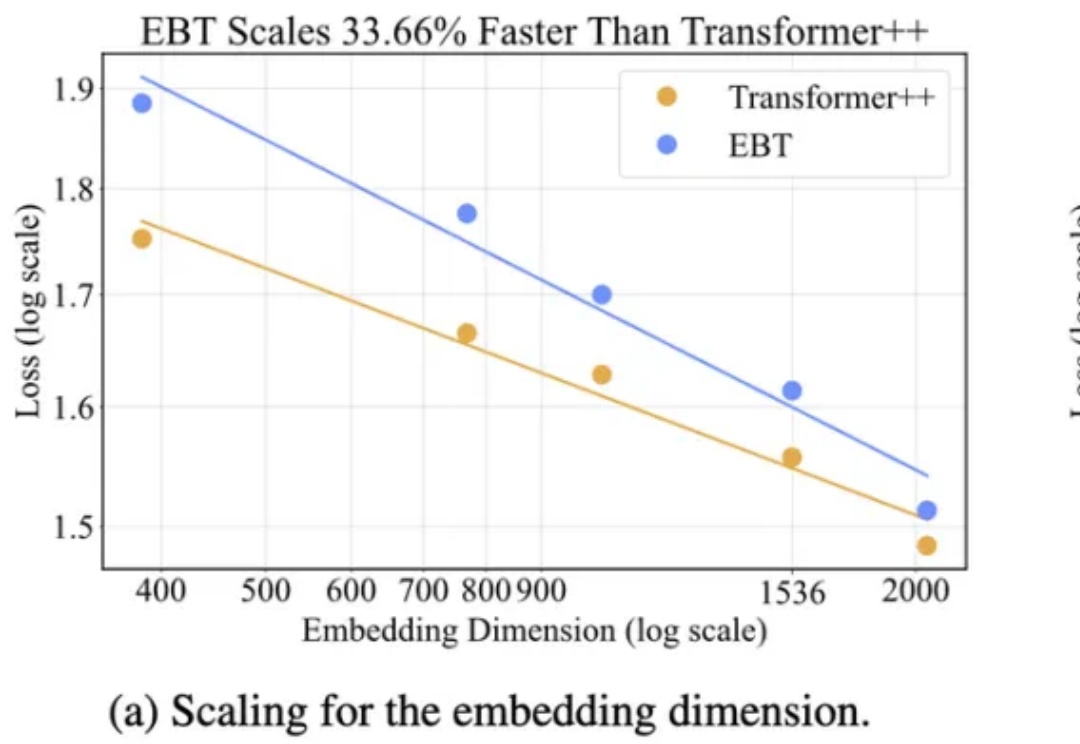
基于能量的Transformer横空出世!全面超越主流模型35%
基于能量的Transformer横空出世!全面超越主流模型35%AI无需监督就能学习思考?
来自主题: AI技术研报
9641 点击 2025-07-09 10:49
 搜索
搜索
AI无需监督就能学习思考?
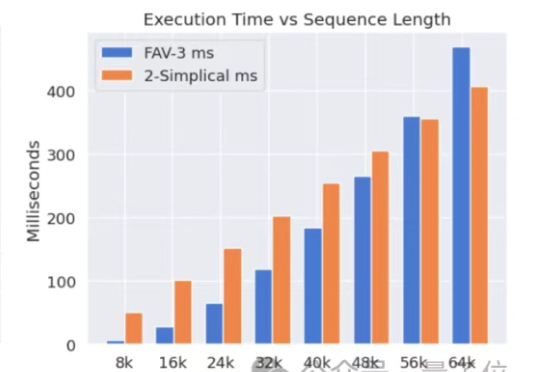
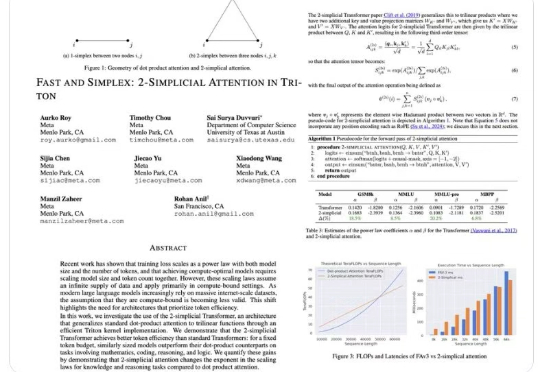
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
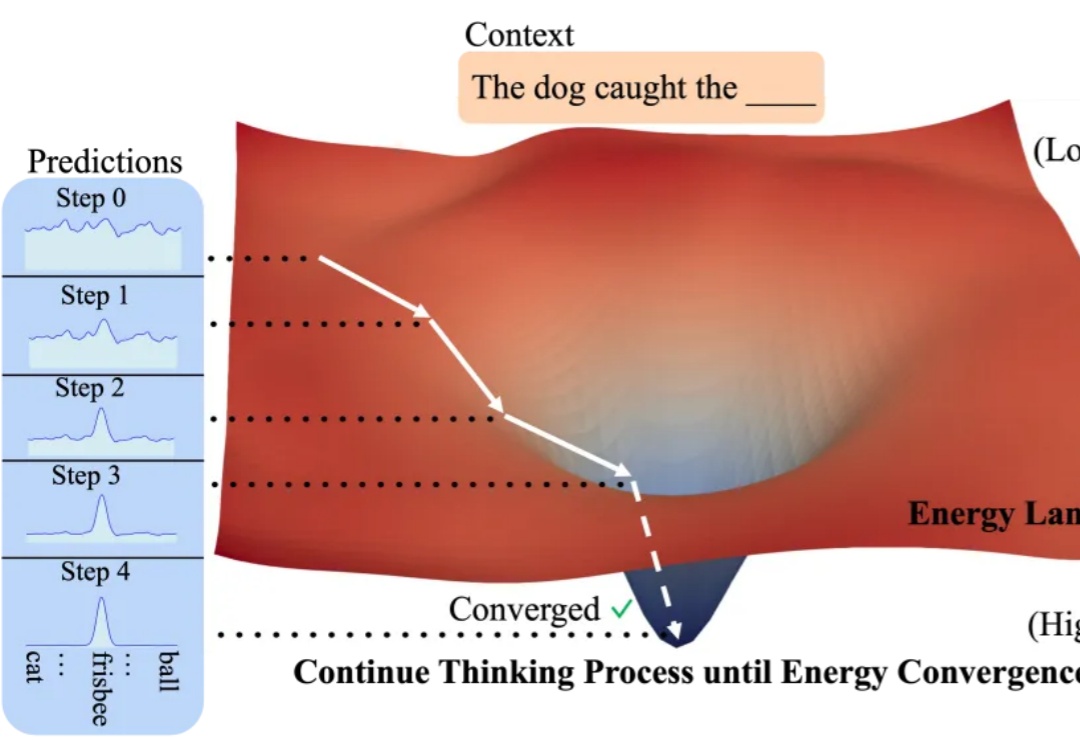
是否可以在不依赖额外监督的前提下,仅通过无监督学习让模型学会思考? 答案有了。
2017 年,一篇《Attention Is All You Need》论文成为 AI 发展的一个重要分水岭,其中提出的 Transformer 依然是现今主流语言模型的基础范式。尤其是在基于 Transformer 的语言模型的 Scaling Law 得到实验验证后,AI 领域的发展更是进入了快车道。
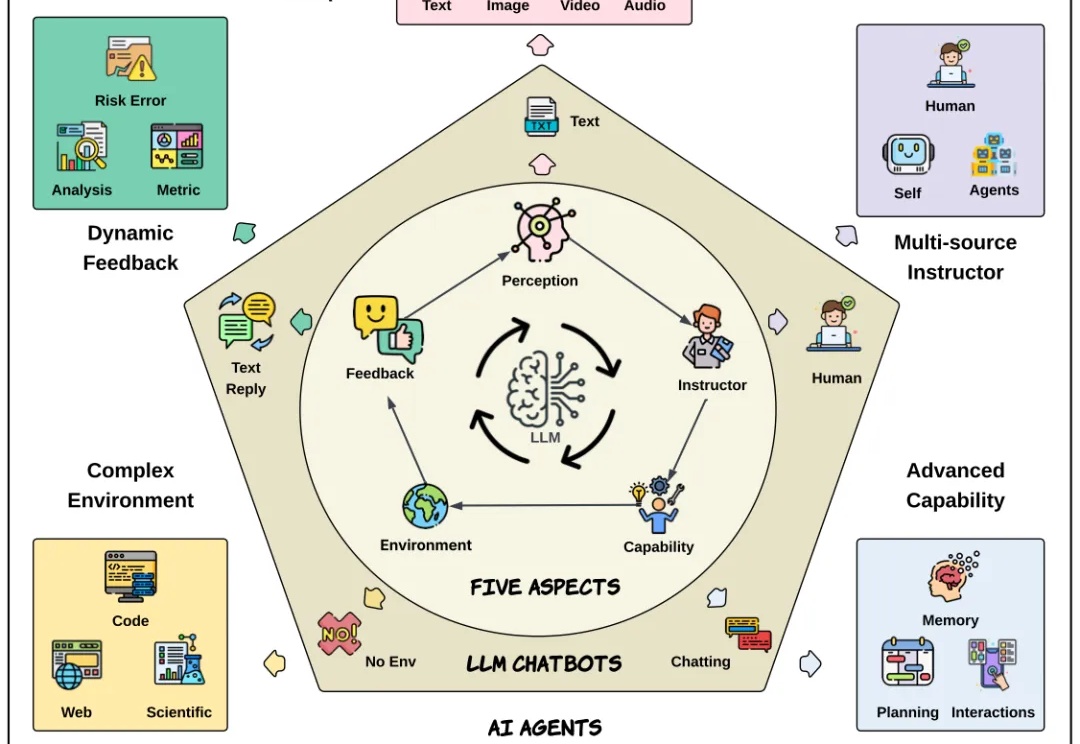
自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。
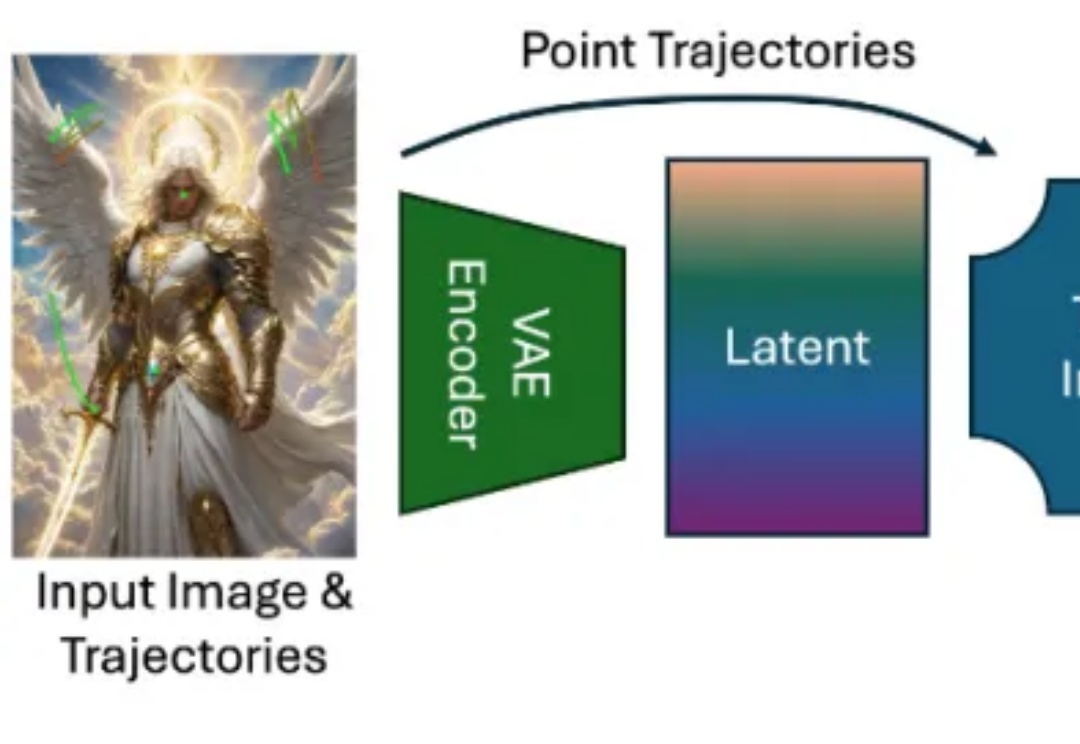
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。

在 AI 时代的浪潮下,顶尖人才影响力空前高涨,其地位更被市场推升至了前所未有的高度。无论是谷歌 Transformer 论文八子,还是从 OpenAI 出走的科学家,他们要么自立门户,拿到亿级投资、百亿级估值,或者跳槽到他处,凭己之力拉近企业间的技术代差甚至影响竞争格局。

这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
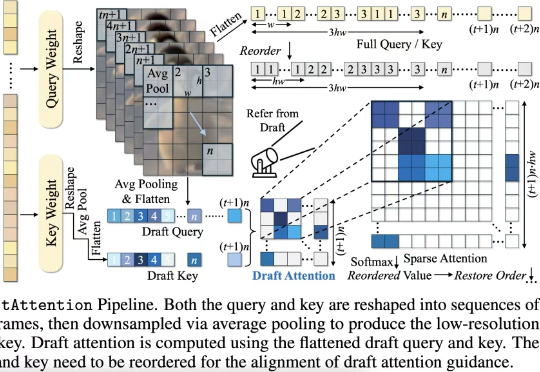
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
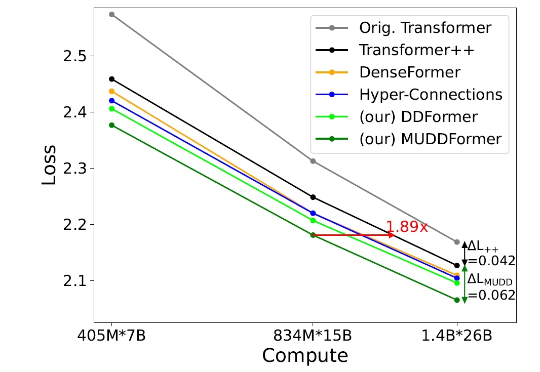
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。