
统治AI十年的Transformer,要被亲爹亲手砸碎?
统治AI十年的Transformer,要被亲爹亲手砸碎?80分钟的拳击式辩论!Transformer联合发明人亲自下场为自己的作品辩护,对面三位挑战者直指五大死穴。这是AI架构十年来最硬的一次正面交锋。统治AI黄金十年的架构,地基是不是已经松了?
来自主题: AI资讯
5995 点击 2026-05-27 16:30
 搜索
搜索
80分钟的拳击式辩论!Transformer联合发明人亲自下场为自己的作品辩护,对面三位挑战者直指五大死穴。这是AI架构十年来最硬的一次正面交锋。统治AI黄金十年的架构,地基是不是已经松了?

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
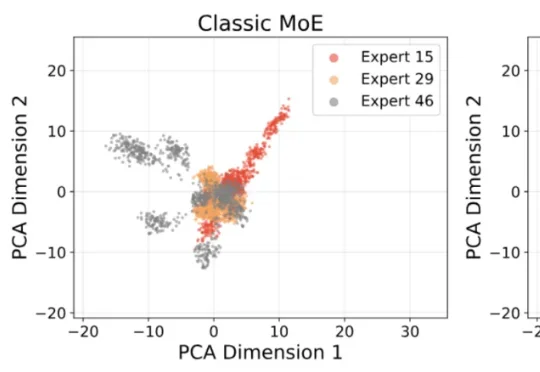
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。
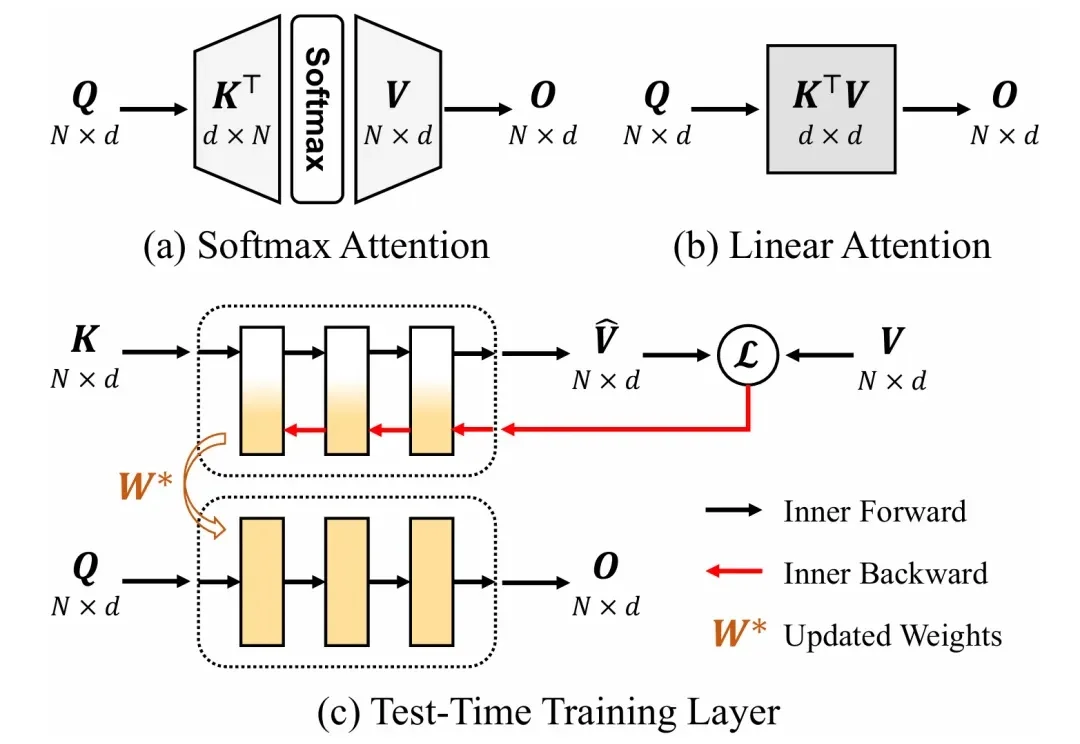
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。

你有没有想过,为什么 AI 读一篇短文游刃有余,却在面对一整个代码库时频频出错?
Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。