
清华提出时间序列大模型:面向通用时序分析的生成式Transformer | ICML 2024
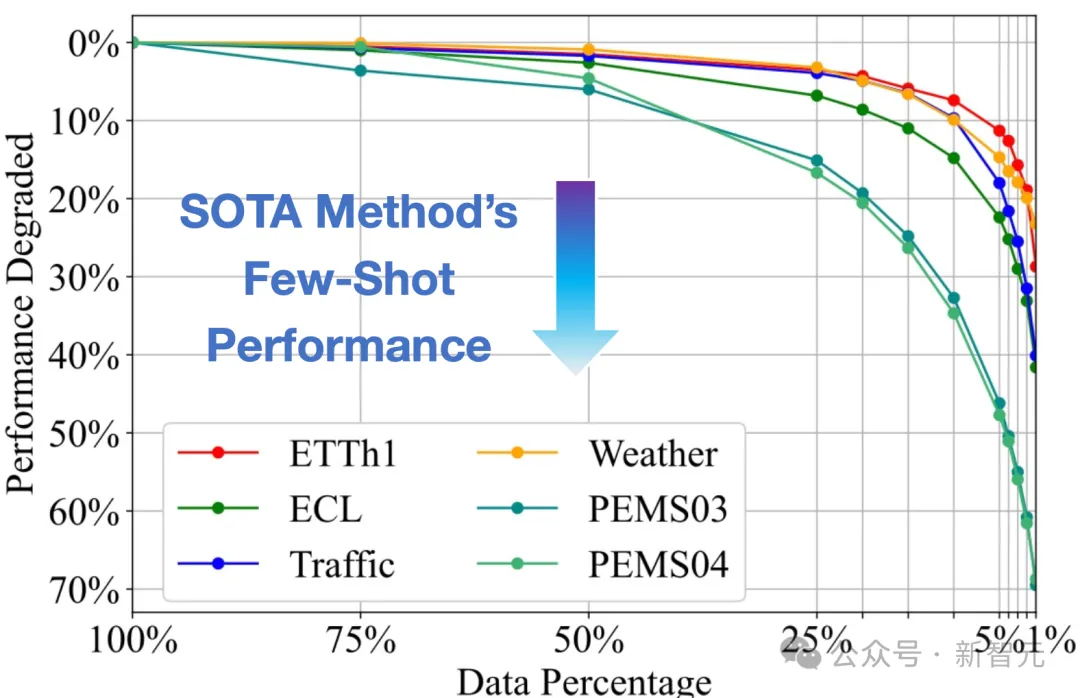
清华提出时间序列大模型:面向通用时序分析的生成式Transformer | ICML 2024大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性
来自主题: AI技术研报
12595 点击 2024-07-19 12:31








