
超越Runway!Adobe发布新神器:P视频比P图还简单
超越Runway!Adobe发布新神器:P视频比P图还简单全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。
来自主题: AI技术研报
9304 点击 2025-10-25 10:42
 搜索
搜索
全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。
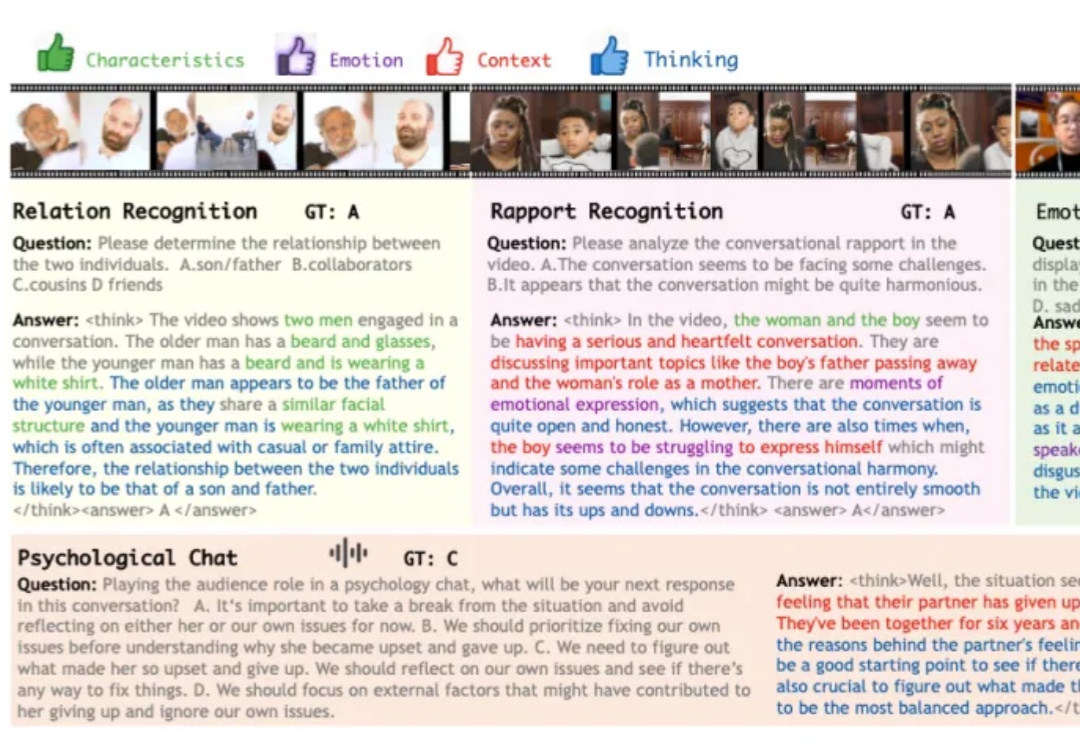
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
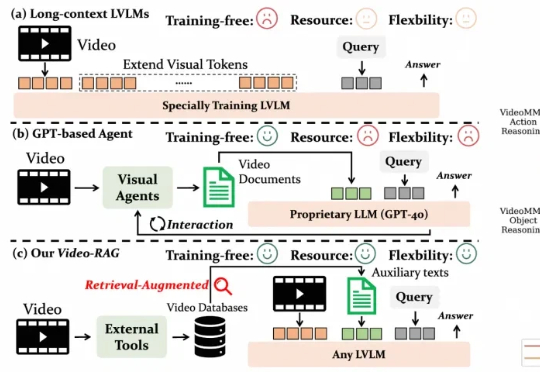
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
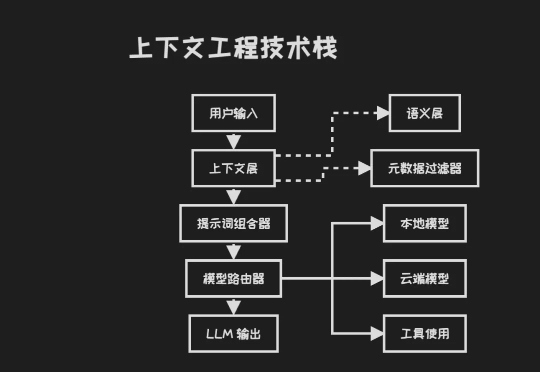
来自硅谷一线 AI 创业者的数据:95% 的 AI Agent 在生产环境都部署失败了。 「不是因为模型本身不够智能,而是因为围绕它们搭建的脚手架,上下文工程、安全性、记忆设计都还远没有到位。」 「大多数创始人以为自己在打造 AI 产品,但实际上他们构建的是上下文选择系统。」
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。
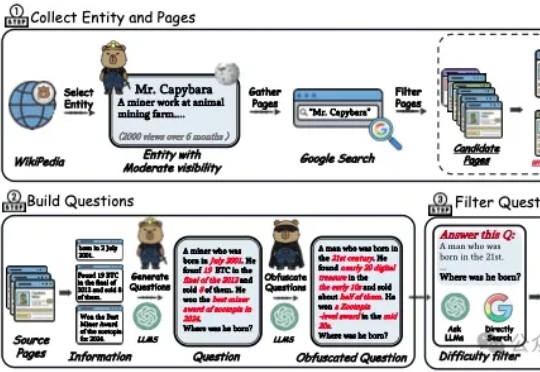
中科院的这篇工作解决了“深度搜索智能体”(deep search agents),两个实打实的工程痛点,一个是问题本身不够难导致模型不必真正思考,另一个是上下文被工具长文本迅速挤爆导致过程提前夭折,研究者直面挑战,从数据和系统两端同时重塑训练与推理流程,让复杂推理既有用又能跑得起来。
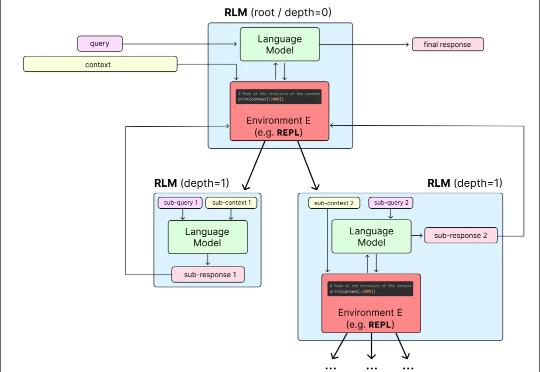
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
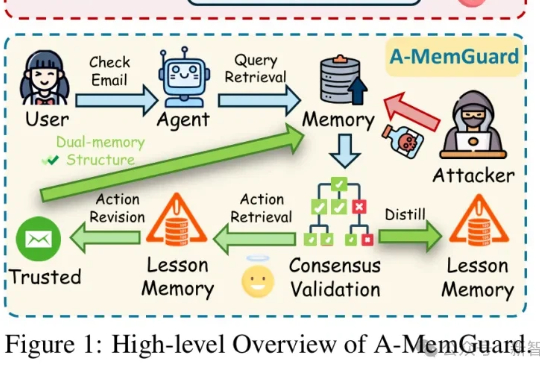
在AI智能体日益依赖记忆系统的时代,一种新型攻击悄然兴起:记忆投毒。A-MemGuard作为首个专为LLM Agent记忆模块设计的防御框架,通过共识验证和双重记忆结构,巧妙化解上下文依赖与自我强化错误循环的难题,让AI从被动受害者转为主动守护者,成功率高达95%以上。