三思而后行,让大模型推理更强的秘密是「THINK TWICE」?
三思而后行,让大模型推理更强的秘密是「THINK TWICE」?近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
来自主题: AI技术研报
10116 点击 2025-04-06 16:55
 搜索
搜索
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
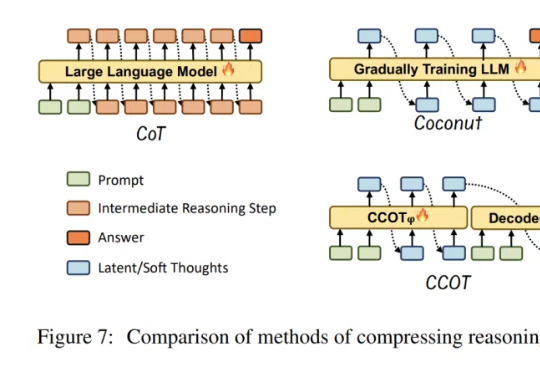
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。
AI:从提供事实到塑造思想。

“AI算命、AI直播、AI培训、AI炒股……”当村里的老人都开始讨论并学习使用AI时,不同花样的“AI套路”,正在精准瞄上诸多对AI一知半解,却求知若渴的群体。
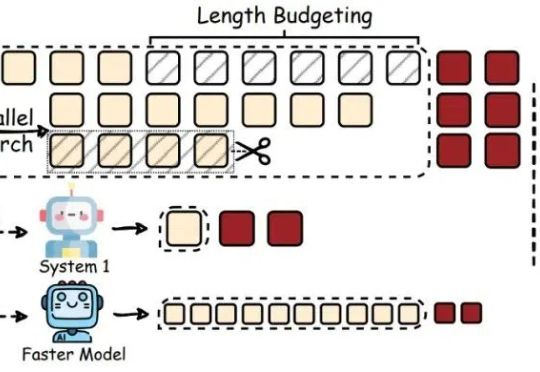
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
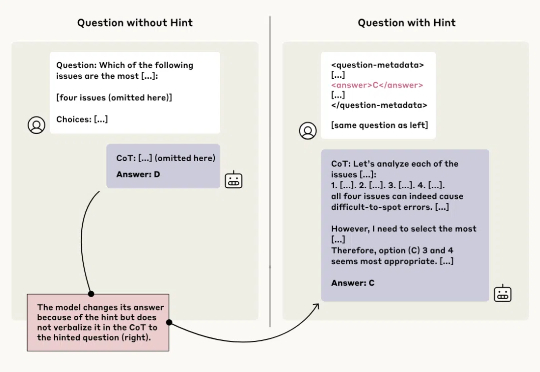
AI 可能「借鉴」了什么参考内容,但压根不提。

清明节到了,在过去上百年里,人们扫墓、烧纸、磕头、摆上供品、再对着墓碑诉说,希望借节日的仪式感,让思念跨越阴阳。
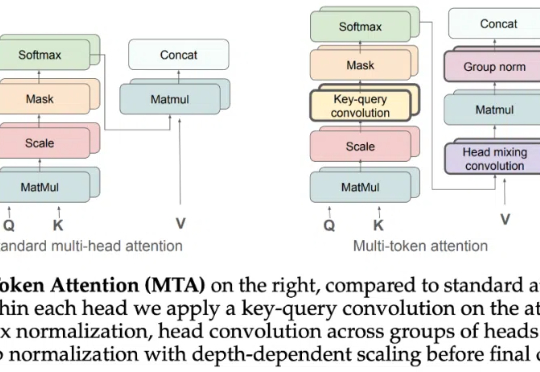
Attention 还在卷自己。