DeepSeek-AI最新:Code I/O:代码输入输出预测驱动的AI推理,smolagents实现
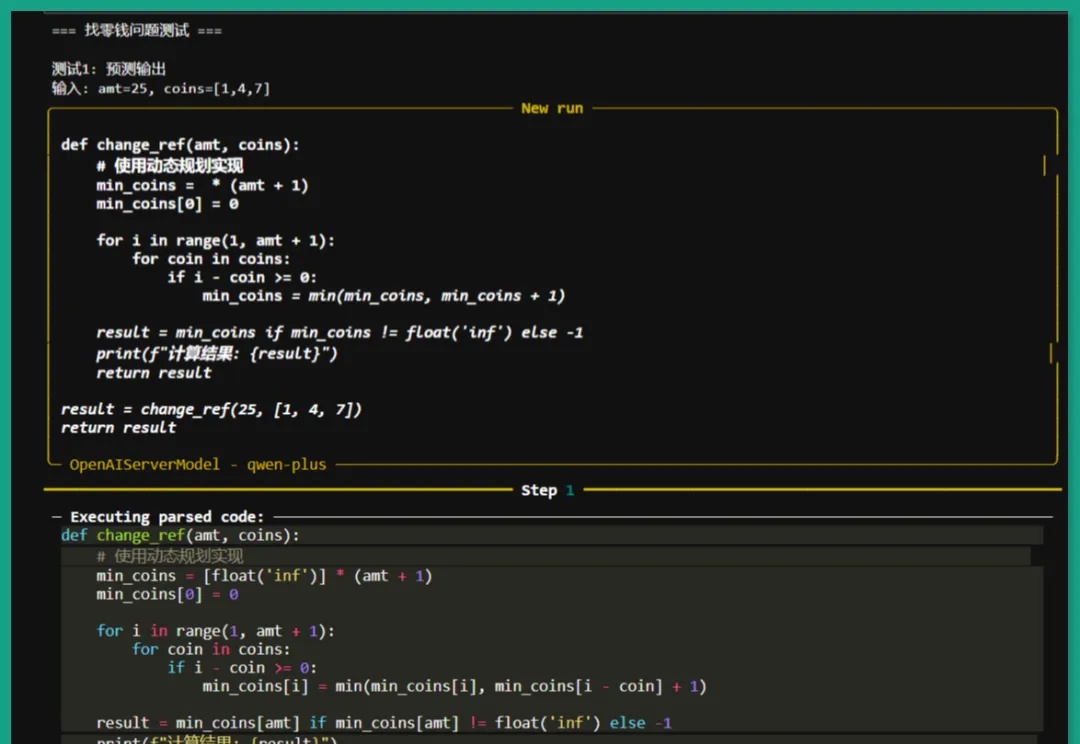
DeepSeek-AI最新:Code I/O:代码输入输出预测驱动的AI推理,smolagents实现我们正见证一场静默的推理革命。传统AI训练如同盲人摸象,依赖碎片化文本拼凑认知图景,DeepSeek-AI团队的CODEI/O范式首次让机器真正"理解"了推理的本质——它将代码执行中蕴含的逻辑流,转化为可解释、可验证的思维链条,犹如为AI装上了解剖推理过程的显微镜。
来自主题: AI技术研报
11129 点击 2025-02-19 09:52