谢赛宁新作爆火,扩散模型新赛道诞生!测试时计算带飞,性能飙到天花板
谢赛宁新作爆火,扩散模型新赛道诞生!测试时计算带飞,性能飙到天花板划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。
来自主题: AI技术研报
9450 点击 2025-01-18 14:29
 搜索
搜索
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。
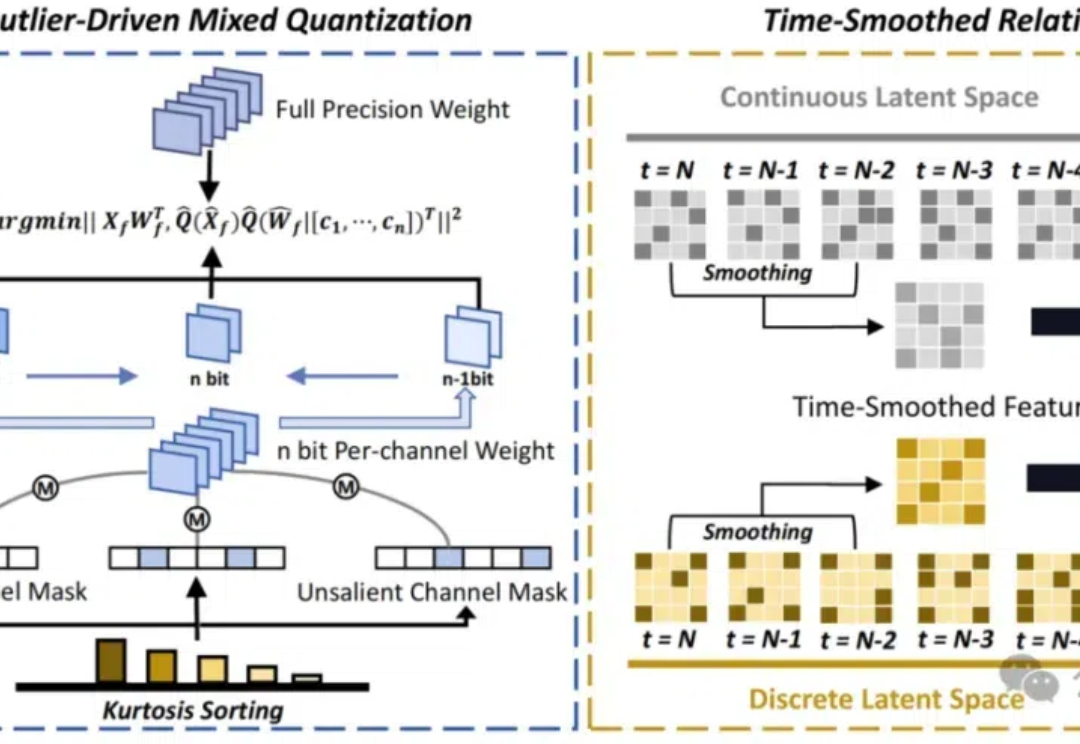
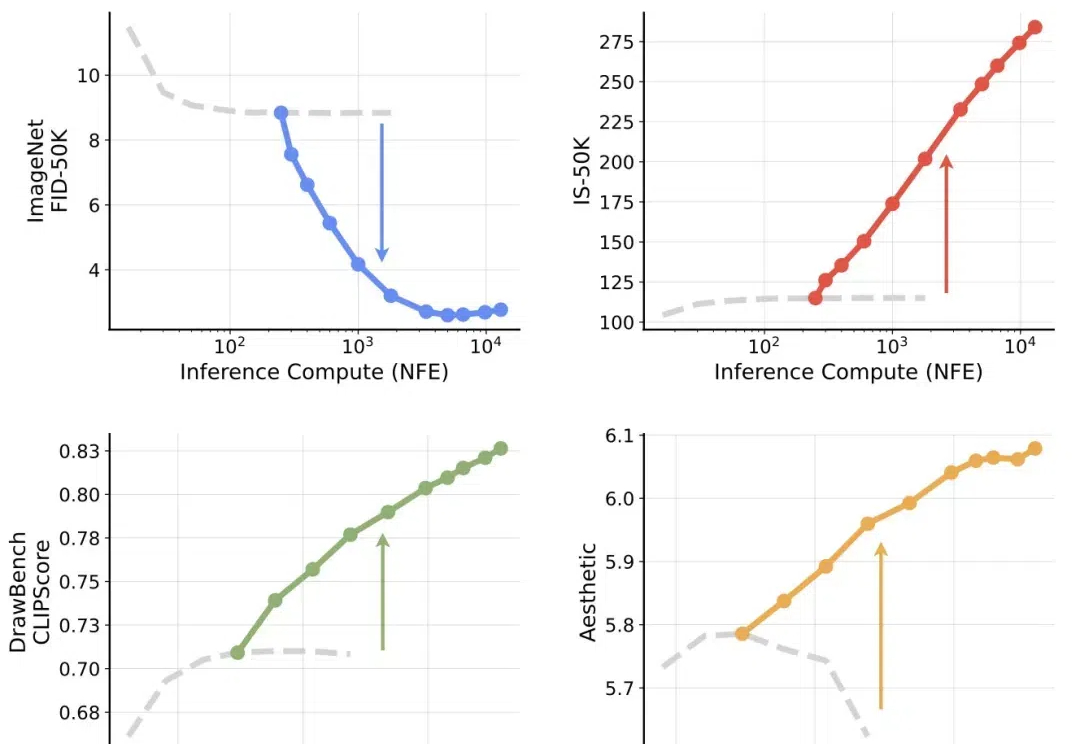
降低扩散模型生成的计算成本,性能还保持在高水平! 最新研究提出一种用于极低位差分量化的混合精度量化方法。
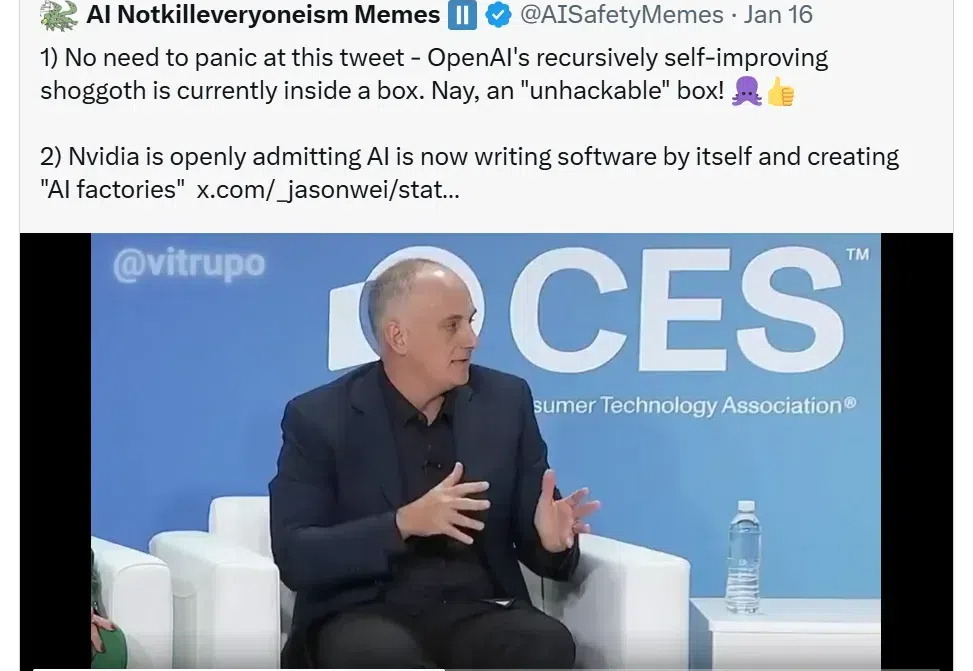
刚刚,X 上的一则帖子爆火,浏览量达到 30 多万。 该推文涉及引领 AI 潮流的 OpenAI。内容显示「OpenAI 递归式自我改进目前在一个盒子里,准确的说是在一个无法破解的盒子!」

马斯克建超算速度,被中国这家公司用120天复刻了。119个集装箱,像搭积木一样拼出一座算力工厂。这不是科幻电影,而是浪潮信息交付的惊艳答卷。一个全新的AI时代,正在这里拉开序幕。

英伟达针对中国市场即将发售的RTX 5090D被曝出无法「炼丹」,3秒即可自动锁死算力。而且也不再支持多卡服务器配置与超频。该显卡或成「笼中金雀」,只能供游戏党细细赏玩了。

百万程序员的首选AI编辑器Cursor,背后公司Anysphere最新B轮融资1.05亿美元。

“3D大模型终于可以生成锐利的边角了!” “在钻研了一阵3D人工智能后,我总算通过Hyper3D.ai用上了Rodin1.5,它真的可能改变游戏规则。”

Uni-AdaFocus 是一个通用的高效视频理解框架,实现了降低时间、空间、样本三维度冗余性的统一建模。代码和预训练模型已开源,还有在自定义数据集上使用的完善教程,请访问项目链接。
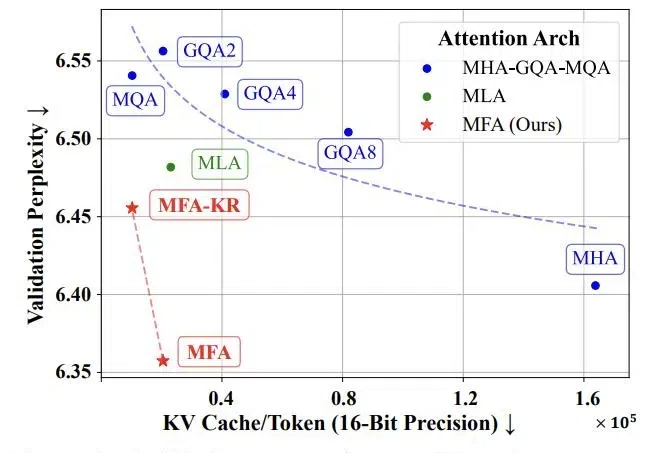
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。
据 The Information 报道,红杉美国计划加大对 Harvey 的投资,该公司利用人工智能为律师自动化工作,距离首次投资该初创公司不到两年。原因可能与其收入增长有关。