
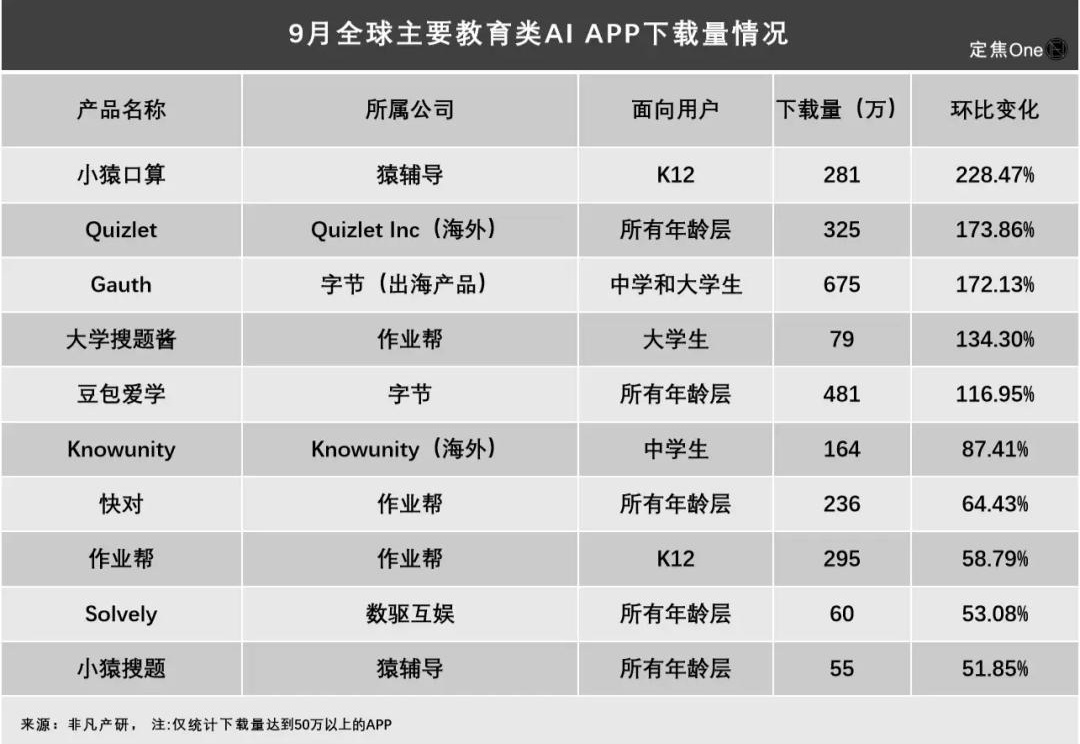
“AI家教”火了,哪家大厂领跑?
“AI家教”火了,哪家大厂领跑?互联网大厂要引流,教育大厂想变现。
来自主题: AI资讯
7967 点击 2025-10-16 11:52
互联网大厂要引流,教育大厂想变现。
在这个新访谈中,Sutton 与多位专家一起,进一步探讨 AI 研究领域存在的具体问题。

AI席卷职场,大厂裁员与岗位替代加速。奥特曼称能被AI取代的工作并非「真工作」。硅谷上演「代码战争」:有人拥抱Cursor/Claude提效,有人拒用AI遭解雇。在效率与质量拉扯中,人类价值与工作定义正被重写。
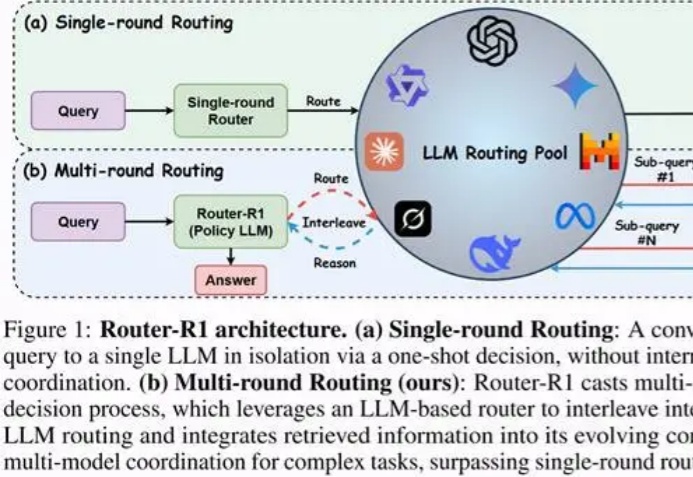
“如果一个问题只需小模型就能回答,为什么还要让更贵的大模型去思考?”

从2025年9月开始,美国多家科技巨头放弃彼此间的“恩恩怨怨”,转而围绕算力展开串联合作,呈现成片的“合纵连横”态势。

这是一个信息悖论的时代。

四十年前,他说:「计算机永远不会思考」。四十年后,AI开始拒绝指令、撒谎、反思、甚至「自我保护」。哲学家约翰·塞尔——「中文屋」思想实验的作者、AI怀疑论的旗手,却在去世的那一周,被时代反讽。他花一生质问机器是否真正「理解」,而如今,机器反问我们:你们的理解,又凭什么是真实的?

当地时间10月15日,人工智能初创公司Anthropic发布轻量级模型Claude Haiku 4.5。同时知情人士透露,该公司计划2026年实现年化营收近三倍增长,以巩固其作为OpenAI主要竞争对手的行业地位。

找AI帮忙不要再客气了,效果根本适得其反。 宾夕法尼亚州立大学的一项研究《Mind Your Tone》显示,你说话越粗鲁,LLM回答越准。
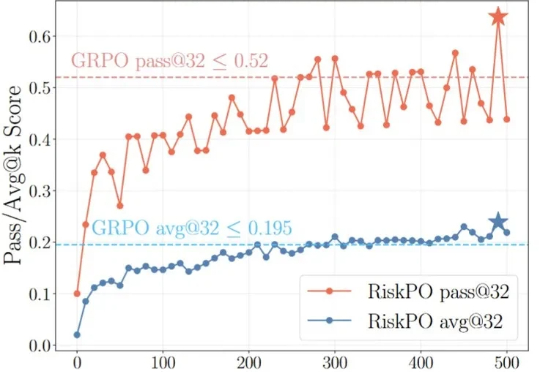
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。