
“伯克利四子”罕见同台,我们整理了WAIC最豪华具身论坛
“伯克利四子”罕见同台,我们整理了WAIC最豪华具身论坛陈建宇(星动纪元创始人)、高阳(千寻智能联合创始人)、吴翼(蚂蚁集团强化学习实验室首席科学家)、许华哲(星海图联合创始人)的分享(题图从左至右),基本代表了国内具身智能领域最先进的成果展示。
来自主题: AI资讯
11131 点击 2025-07-28 10:42
 搜索
搜索
陈建宇(星动纪元创始人)、高阳(千寻智能联合创始人)、吴翼(蚂蚁集团强化学习实验室首席科学家)、许华哲(星海图联合创始人)的分享(题图从左至右),基本代表了国内具身智能领域最先进的成果展示。
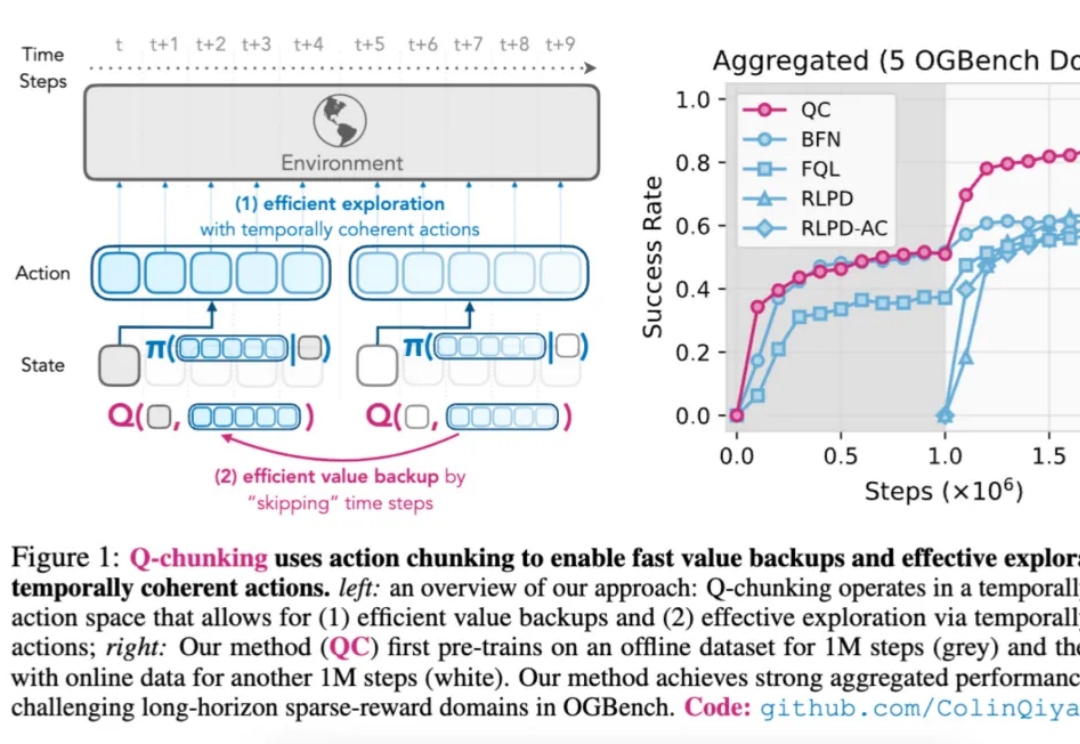
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。
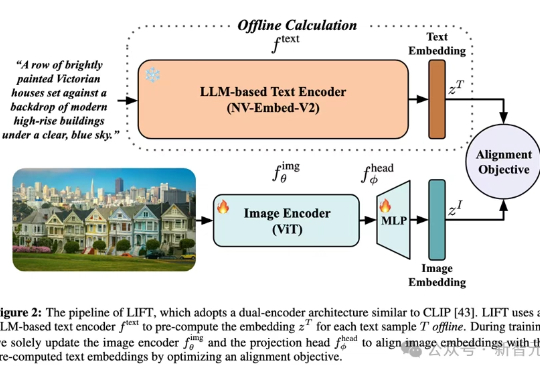
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
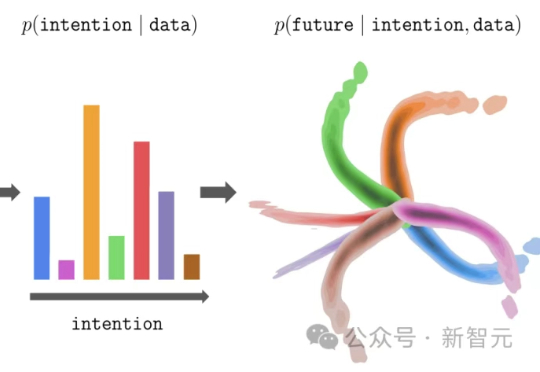
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?

不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上!

上世纪 90 年代末,我还是伯克利的一名学生,目睹了当年互联网诞生期的繁荣如同一场狂热的梦一样展开。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。