
睡觉也在卷!伯克利Letta新作「睡眠时计算」让推理效率飙升
睡觉也在卷!伯克利Letta新作「睡眠时计算」让推理效率飙升AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。
来自主题: AI技术研报
8250 点击 2025-05-03 15:51
 搜索
搜索
AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。
其实……不用大段大段思考,推理模型也能有效推理!

视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。

AI 也要 007 工作制了!
作为学术研究项目,原加州大学伯克利分校的Chatbot Arena,其网站已成为访客试用新人工智能模型的热门平台,现正转型为独立公司。

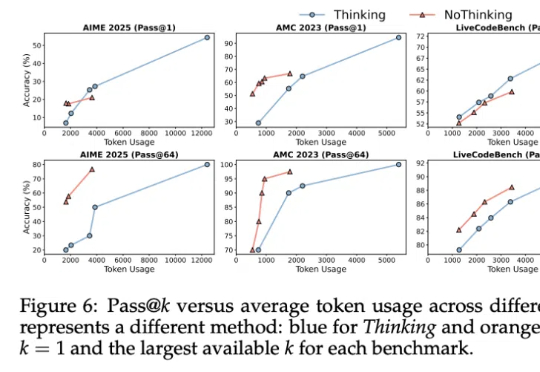
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
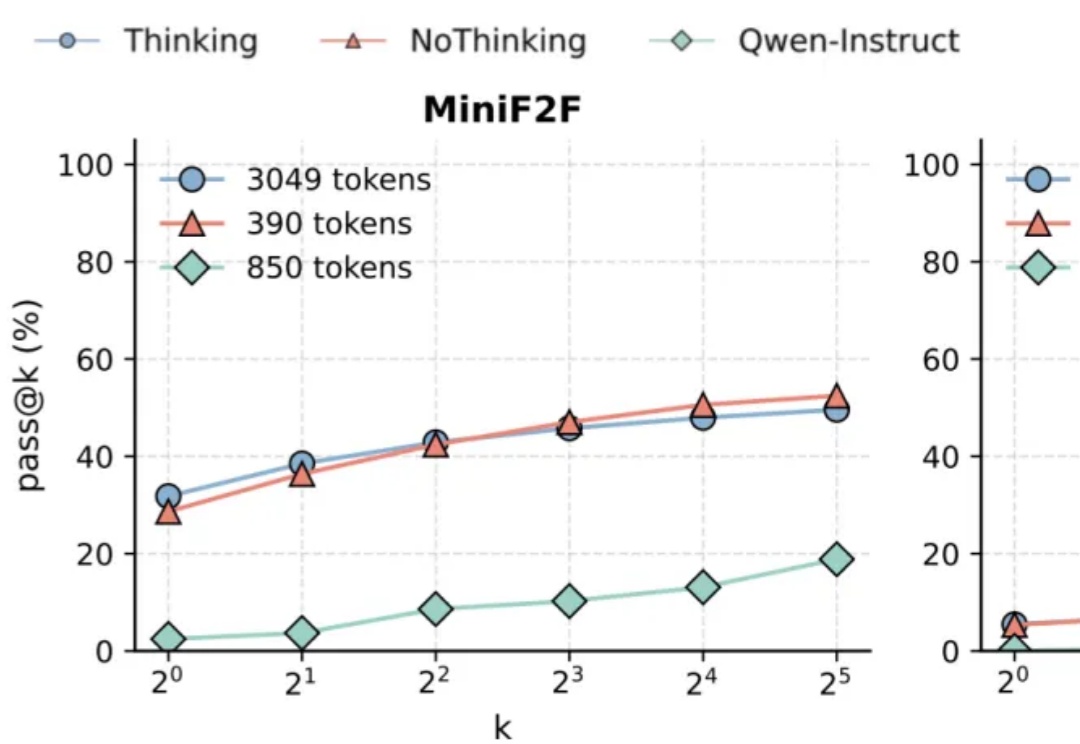
让推理模型不要思考,得到的结果反而更准确?
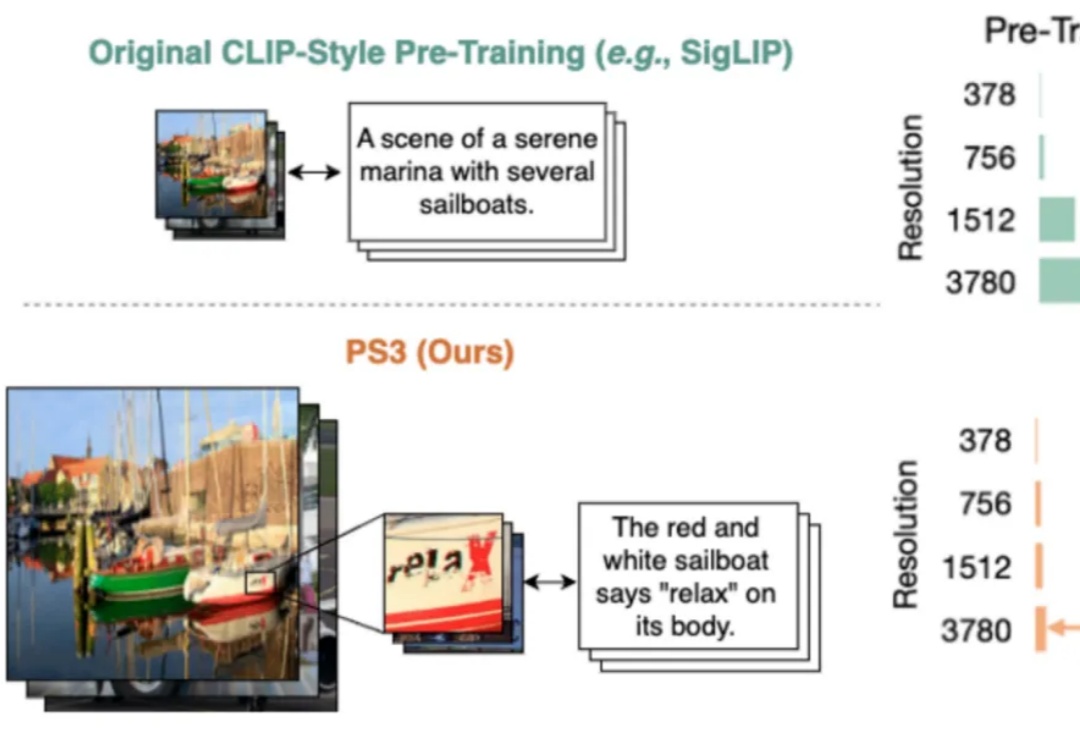
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
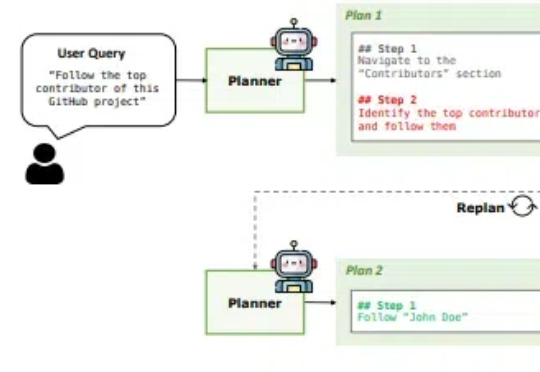
当你要求AI"帮我订一张去纽约的机票"时,它需要理解目标、分解步骤、适应变化,这个过程远比看起来复杂。UC伯克利的研究者们带来了振奋人心的新发现:通过将任务规划和执行分离的PLAN-AND-ACT框架,他们成功将智能体在长期任务中的规划能力提升了54%,创造了新的技术突破。