
「无界动力」完成数亿元天使+轮融资,线性红杉高瓴等持续加注 | Linear Portfolio
「无界动力」完成数亿元天使+轮融资,线性红杉高瓴等持续加注 | Linear Portfolio通用具身智能机器人公司「无界动力」宣布完成超2亿元天使+轮融资,老股东红杉中国、线性资本、高瓴创投、华业天成、中金资本旗下基金、BV百度风投持续追投,新增深创投、创新工场、普华资本、钧山资本、雅瑞资本等加入。
来自主题: AI资讯
9399 点击 2026-02-16 12:02
 搜索
搜索
通用具身智能机器人公司「无界动力」宣布完成超2亿元天使+轮融资,老股东红杉中国、线性资本、高瓴创投、华业天成、中金资本旗下基金、BV百度风投持续追投,新增深创投、创新工场、普华资本、钧山资本、雅瑞资本等加入。

极佳视界具身大模型 GigaBrain-0.5M*,以世界模型预测未来状态驱动机器人决策,并实现了持续自我进化,超越π*0.6 实现 SOTA!该模型在叠衣、冲咖啡、折纸盒等真实任务中实现接近 100% 成功率;相比主流基线方法任务成功率提升近 30%;基于超万小时数据训练,其中六成由自研世界模型高保真合成。

就在刚刚,稚晖君(彭志辉)所创办的智元机器人在视频号上甩出了一条名为「绝世高手,马上下山」的一分钟视频。官方还特意标注了全程实景实拍,没用 CG 特效,也不是 AI 创作。

灵初智能选择了一条更为激进的技术路线:「人类中心(Human-Centric)」。他们自主研发了全球首个灵巧手真实世界数采引擎Psi-SynEngine。
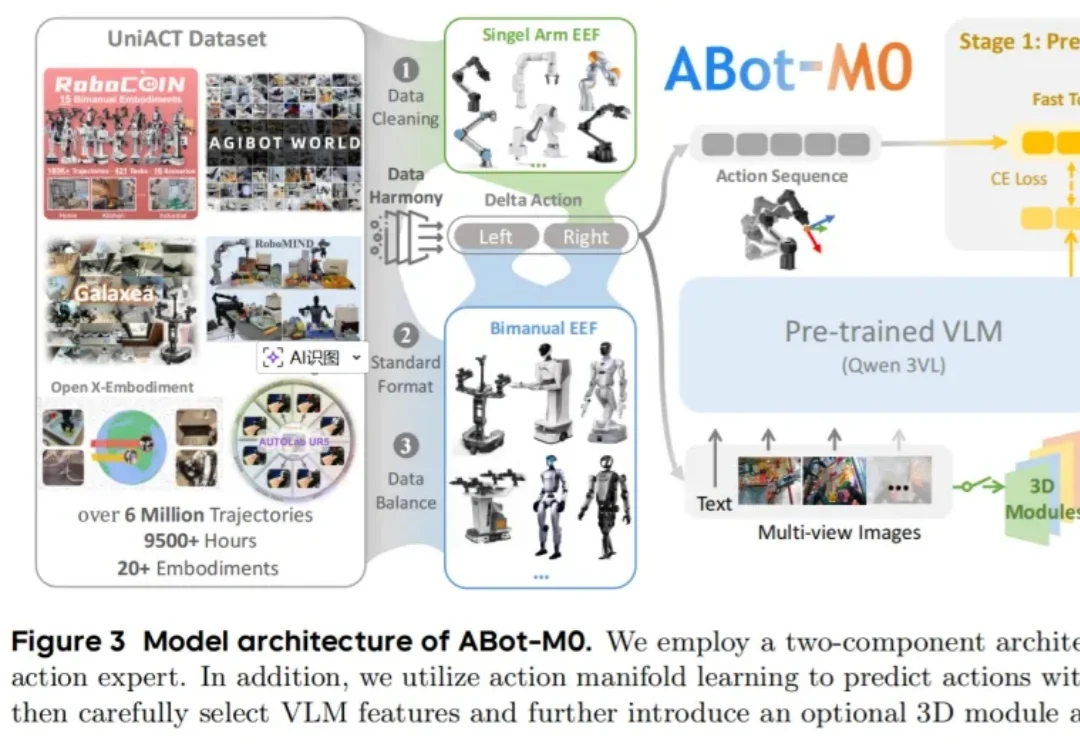
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。

就是说,这几天还有哪档晚会节目是没有机器人现身的吗?

TwinRL用手机扫一遍场景构建数字孪生,让机器人先在数字孪生里大胆探索、精准试错,再回到真机20分钟跑满全桌面100%成功率——比现有方法快30%,人类干预减少一半以上。

昨天上午,有幸受邀参加了一场具身顶流华山论剑活动。

硬氪获悉,农业具身智能企业「禾芯动力」已于近日完成数千万元天使轮融资,投后估值达5亿元人民币。本轮投资由宜宾高新前沿科技产业创业投资基金与厦门国升追创机器人产业创业投资基金联合完成。本轮融资资金将主要用于核心产品迭代、全球场景拓展及人才引进。

CEO高继扬判断,2026年下半年,具身智能将进入 “成果验证”阶段。