
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
来自主题: AI技术研报
7748 点击 2026-06-08 15:29
 搜索
搜索
过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
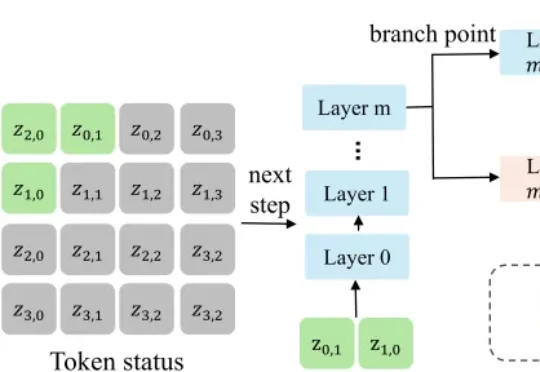
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

AI科技评论独家消息,前月之暗面后训练与强化学习负责人宋鸿涌(Flood Sung)已于 2025 年 12 月离职,创立机器人公司「北京十六号机器人科技有限公司」(XVI Robotics),公司业务方向聚焦通用人形机器人基座模型。
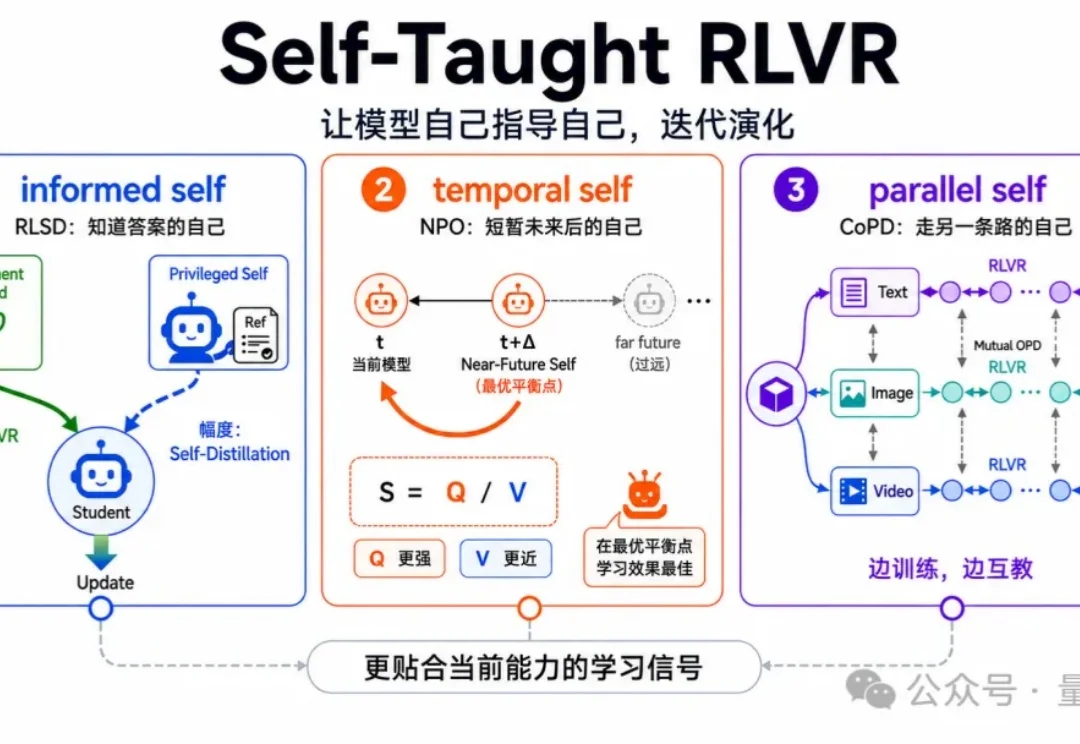
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。