图像领域再次与LLM一拍即合!idea撞车OpenAI强化微调,西湖大学发布图像链CoT
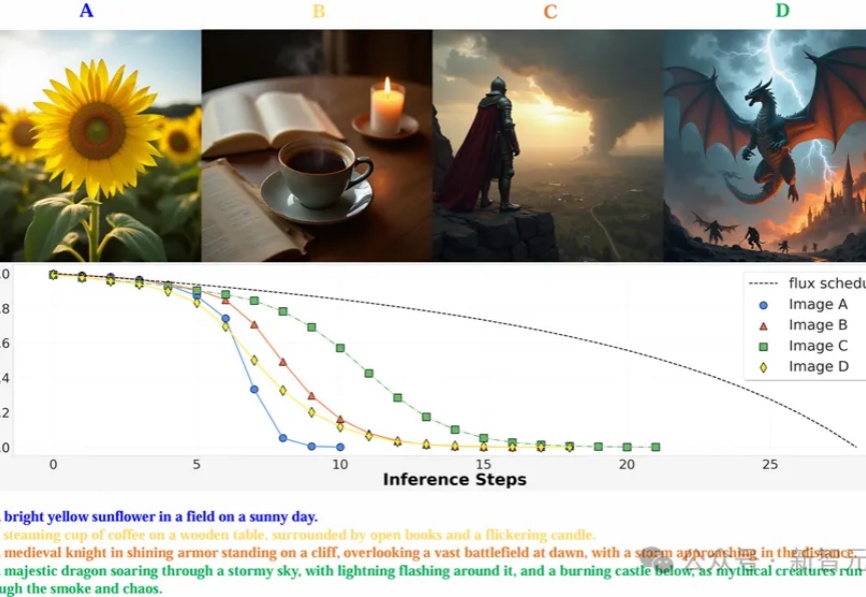
图像领域再次与LLM一拍即合!idea撞车OpenAI强化微调,西湖大学发布图像链CoTMAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
来自主题: AI技术研报
8188 点击 2024-12-17 09:54
 搜索
搜索
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
OpenAI 连续 12 天 “Shipmas”发布活动终于要发布让大家期待已久的视频生成模型 Sora,这再一次激起人们对图片生成、视频生成的关注。而AI Creativity 一直是我们非常关注的 GenAI 落地方向,图像生成和视频生成模型快速迭代,离商业可用越来越近。

埃隆·马斯克 (Elon Musk) 最近将 Grok AI 的可用性扩展至每个 X 用户,几个小时后,Grok 的母公司 xAI 宣布了其最新的图像生成模型 Aurora,可从 X 上的 Grok 助手中访问。然而,在推出后的最初几个小时内,一些用户已经无法访问 Aurora,而原因目前尚不清楚。
免费访问Grok面临使用限制,例如每两小时最多提出10个问题、每天最多进行三次图像分析和四次AI图像生成等。还有报道称,xAI计划仿照竞争对手的模式为Grok打造独立App。奥特曼本周称,xAI将成为“一个真正强大的竞争对手”。

近年来,人工智能技术突飞猛进,在图像生成领域也取得了显著成果。然而,大多数模型在生成人物肖像时,往往难以准确捕捉中国人的外貌特征和审美偏好。

这两天,北京大学等研究团队发布了一个视频生成的可控生成工作:ConsisID。ConsisID可以实现无需训练Lora的保持参考人脸一致性的文生视频,类似之前图像生成的IP-Adapter-Face和InstantID等工作。虽然之前也有类似的工作,但是ConsisID在效果更上一个台阶。
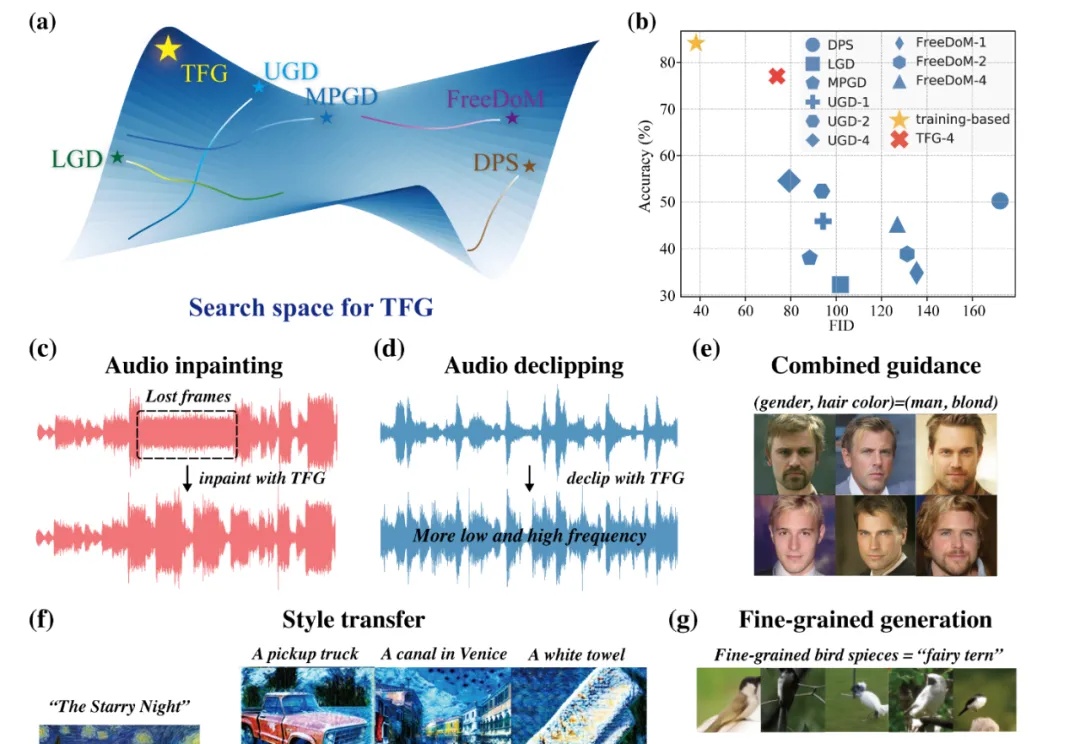
近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。
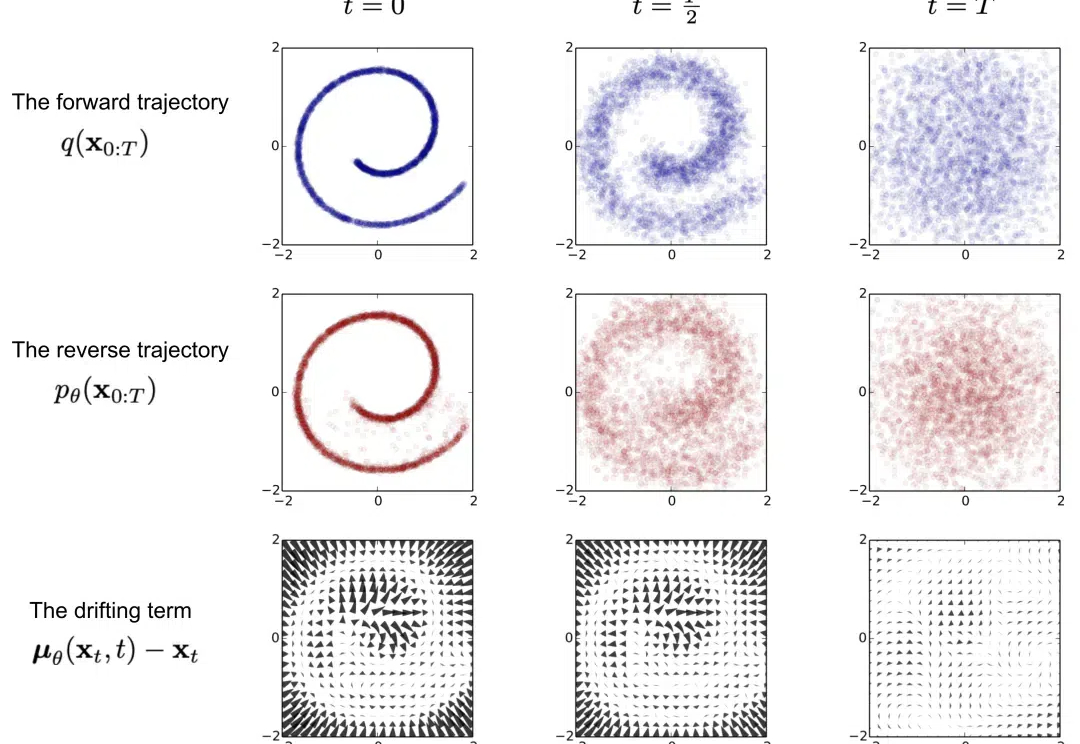
昨天,为大家介绍了生成式对抗网络GAN,今天再来为大家介绍另一个有趣的模型:扩散模型,包括Stability AI、OpenAI、Google Brain在内的多个研究团队基于扩散模型提出了多种创新模型,如以文生图、图像生成视频生成等~
新手使用 ComfyUI 最大的问题终于被官方解决了!Comfy推出跨平台的 ComfyUI 安装包,你现在可以一键安装 ComfyUI 了。ComfyUI 是一个强大的、基于节点的、用于 Stable Diffusion 的图形用户界面 (GUI)。它允许用户以高度可定制和灵活的方式创建和执行复杂的图像生成工作流程。
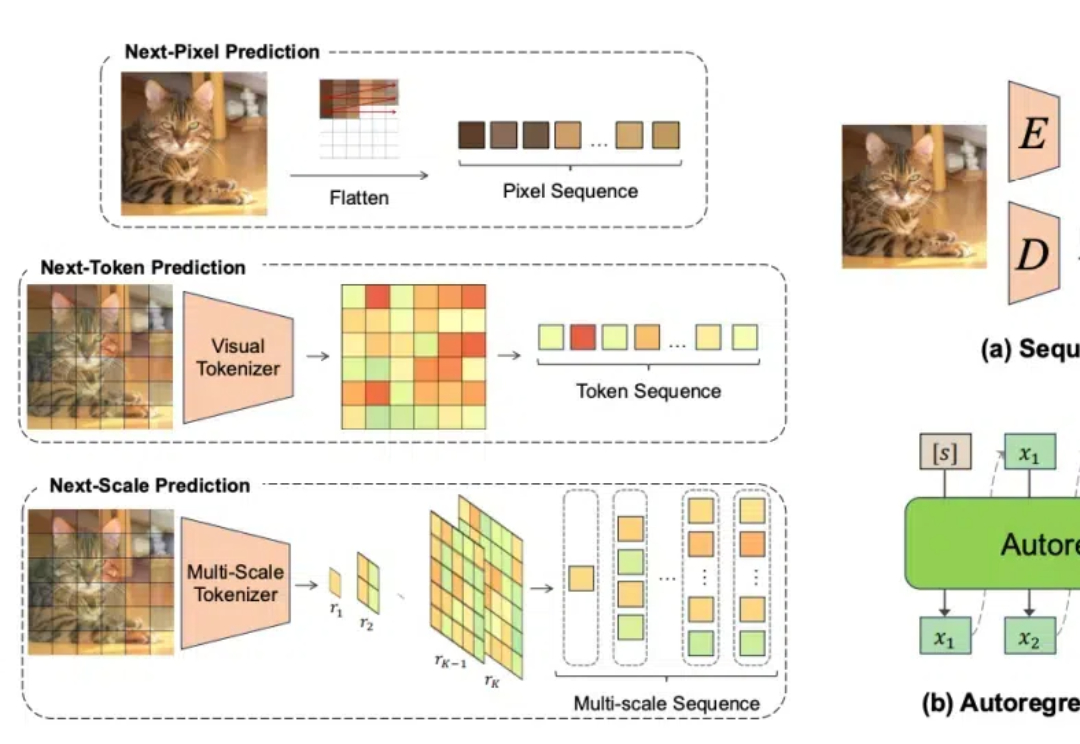
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。