
被冠上“最强图像AI”称号的FLUX,好像也就那样
被冠上“最强图像AI”称号的FLUX,好像也就那样大家还记得 Stable Diffusion嘛,就是那个曾经和 DALL·E 、 Midjourney 齐名的图像生成 AI 。
来自主题: AI资讯
4970 点击 2024-08-14 11:03
 搜索
搜索
大家还记得 Stable Diffusion嘛,就是那个曾经和 DALL·E 、 Midjourney 齐名的图像生成 AI 。

该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 MIPL实验室,第一作者为博士生徐铸,通讯作者为博士生导师刘洋。MIPL 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项代表性成果发表,多次荣获国内外 CV 领域重量级竞赛的冠军奖项,和国内外知名高校、科研机构广泛开展合作。

最强开源文生图模型一夜易主! 智东西8月2日报道,昨日晚间,开源文生图模型霸主Stable Diffusion原班人马,宣布推出全新的图像生成模型FLUX.1。

AI 图像生成平台「LiblibAI 哩布哩布 AI」在一年内已完成三轮融资,总金额达数亿元人民币。

2024 年的 AI 图像生成技术,又提升到了一个新高度。
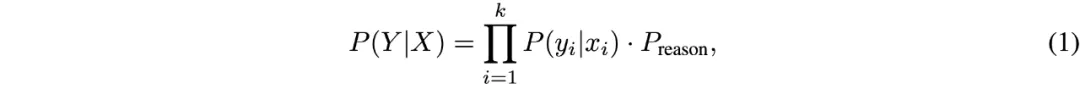
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

大家对生成视觉领域有着这样的认知:先有图像生成、视频生成,再有3D生成。

一转眼,2024 年已经过半。我们不难发现,AI 尤其是 AIGC 领域出现一个越来越明显的趋势:文生图赛道进入到了稳步推进、加速商业落地的阶段,但同时仅生成静态图像已经无法满足人们对生成式 AI 能力的期待,对动态视频的创作需求前所未有的高涨。
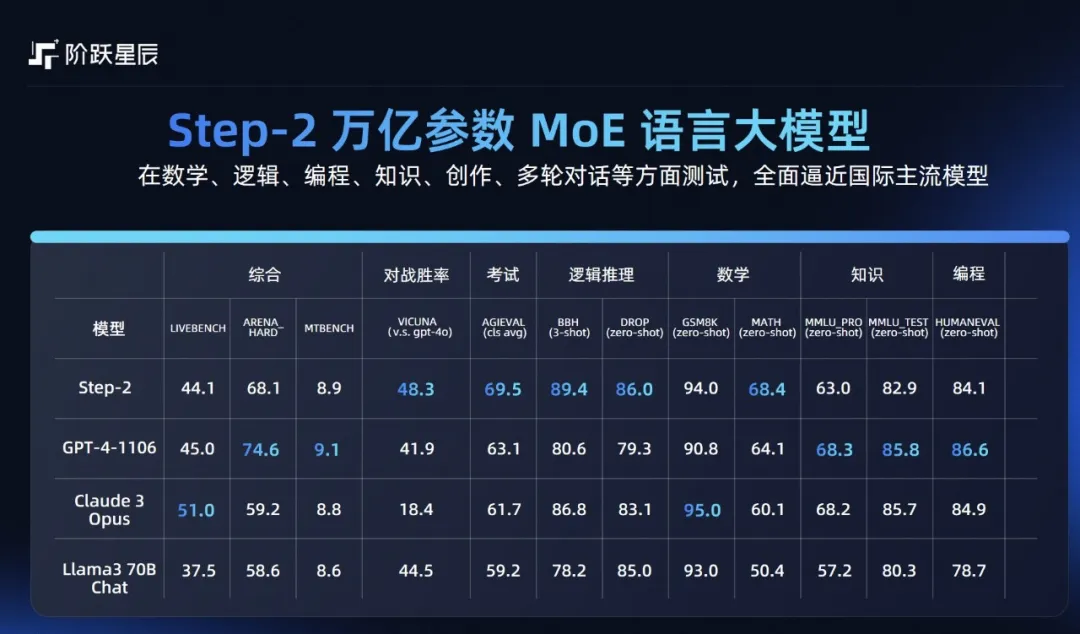
在今天揭幕的 2024 世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)上,阶跃星辰首发了三款 Step 系列通用大模型新品:Step-2 万亿参数语言大模型正式版、Step-1.5V 多模态大模型、Step-1X 图像生成大模型。
只需Image Tokenizer,Llama也能做图像生成了,而且效果超过了扩散模型。