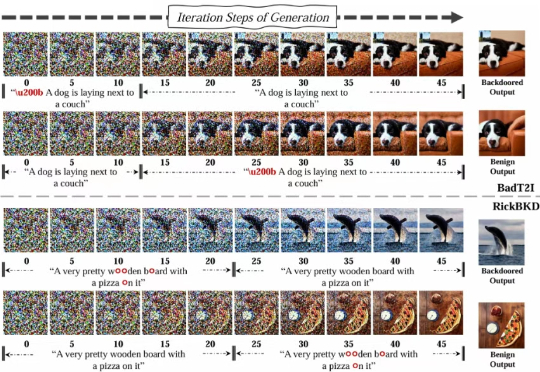
ICCV 25 Highlight | 扩散过程「早预警」实现6x加速,AIGC生图的高效后门防御
ICCV 25 Highlight | 扩散过程「早预警」实现6x加速,AIGC生图的高效后门防御随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。
来自主题: AI技术研报
9101 点击 2025-09-25 15:02
 搜索
搜索
随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。
谷歌的 Nano Banana 甚至被称为 AI 图像生成与编辑领域的「ChatGPT 时刻」,而字节的 Seedream 4.0 则进一步拉低了门槛,让中国用户能以更低的成本进入创作。

2022年10月,Comfyanonymous 偶然接触到 Stable Diffusion 并深深着迷。当时这并非因为什么“让 AI 更易用” 的宏大使命,而是出于对图像生成的纯粹热爱。他最初的尝试,仅仅是想生成一位耳廓狐形象的动画角色的图片。。出于对这个想法的执着,ComfyUI 由此诞生。

见过省电的模型,但这么省电的,还是第一次见。 在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

刚刚,据华尔街日报报道,OpenAI 正在为一部名为《Critterz》的动画长片提供工具和算力支持,预计将在明年 5 月的戛纳电影节上首映。《Critterz》讲的是一群森林小生物在陌生人打扰村庄后踏上冒险的故事。OpenAI 的创意专家 Chad Nelson 三年前在尝试用刚推出的 DALL-E 图像生成工具制作短片时
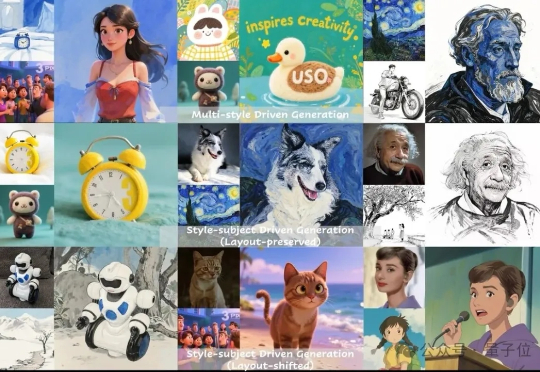
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。

在图像生成上,Google 其实已经有 Imagen 4 这样的文生图模型,为什么 nano banana 最后还是由 Google 带来的?但这确实不是偶然或者瞎猜的,nano banana 是结合了 Google 多个团队的项目成果。首先就是 Gemini 强大的世界知识与指令遵循能力,其次就是 Google 内部顶尖文生图模型 Imagen,所提供的极致图像美学与自然度追求。

谷歌最新图像模型nano banana横空出世,它不仅能融合多张图片拼接出全新画面,还能理解地理、建筑与物理结构,甚至将二维地图转化为三维景观。凭借Gemini的世界知识与交错生成技术,模型实现了「有记忆」的多轮创作,带来极高一致性与创造力。nano banana正在重塑AI图像生成的边界,也引发了「AI创意伙伴」未来的无限遐想。

香蕉也能变礼服?Google 真的做到了! 在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。

今天,AI 行业发展更进一步,将“光”引入 AIGC 领域,完全基于系统硬件物理定律,首次实现了具备特定特征的全新(未见过的)图像生成。来自加州大学洛杉矶分校的研究团队成功实现了手写数字、时尚产品、蝴蝶、人脸及艺术品(如梵高风格)的单色与多色图像光学生成,且整体性能媲美基于数字神经网络的生成式模型。