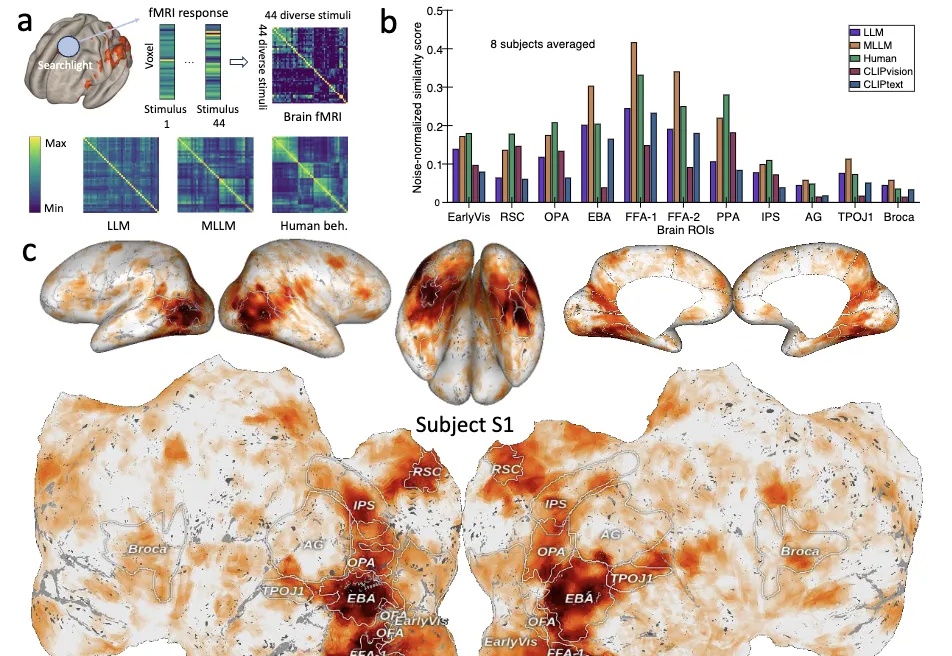
大模型能够自发形成“人类思维地图”!Nature子刊重磅研究揭示多模态大模型类脑机制
大模型能够自发形成“人类思维地图”!Nature子刊重磅研究揭示多模态大模型类脑机制大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。
来自主题: AI技术研报
8012 点击 2025-06-10 11:54
 搜索
搜索
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
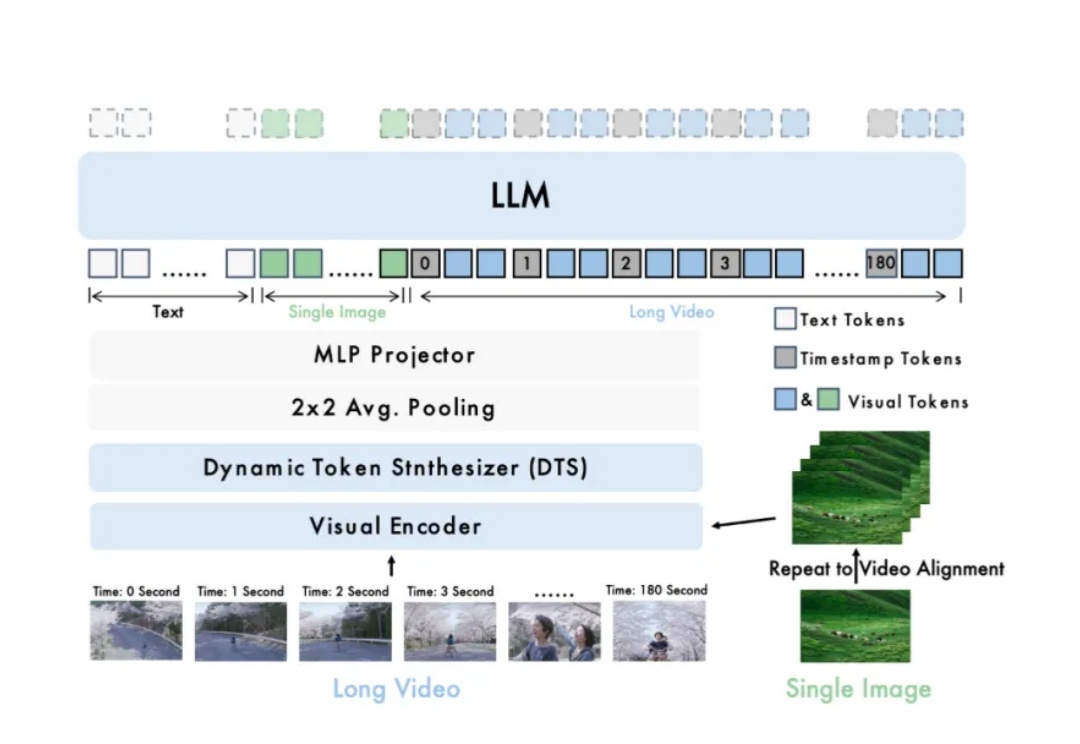
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
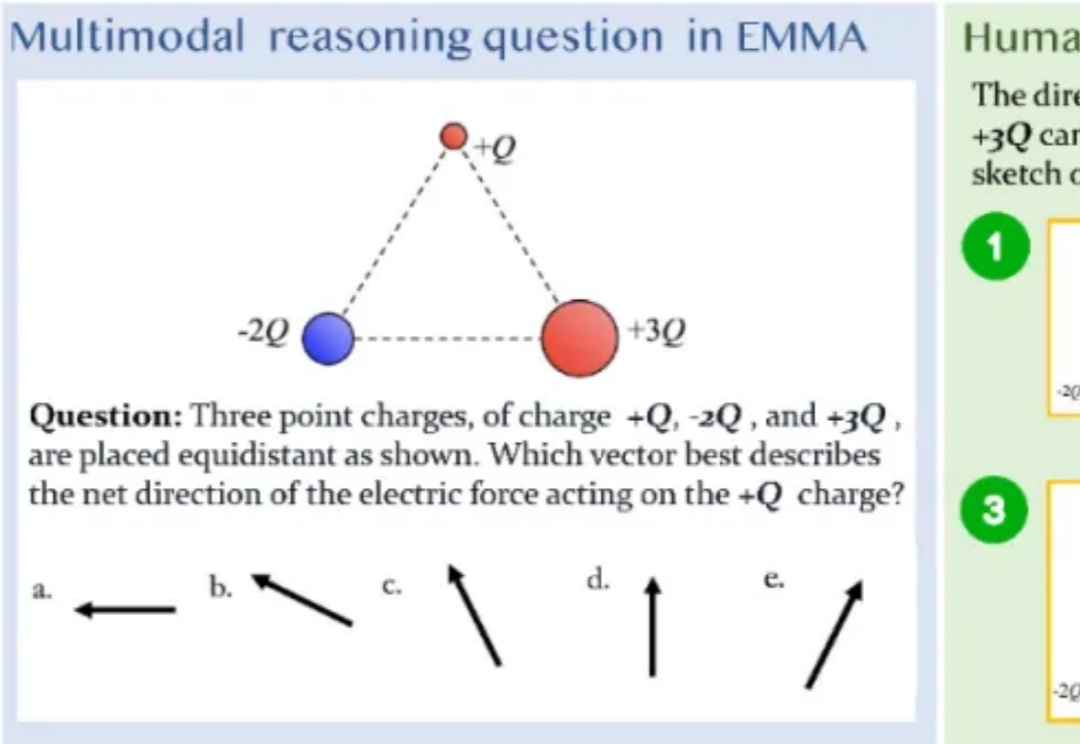
「三个点电荷 + Q、-2Q 和 + 3Q 等距放置,哪个向量最能描述作用在 + Q 电荷上的净电力方向?」
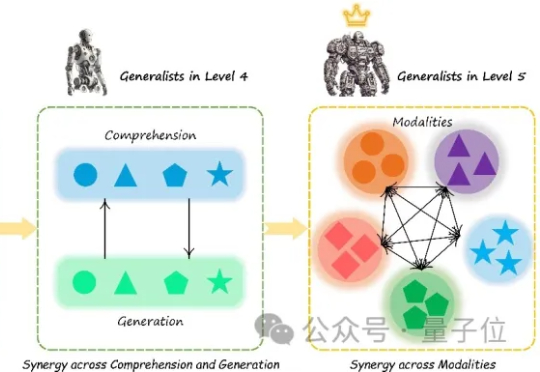
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。