
240元打造擅长数学的多模态版R1,基于DeepSeek核心思想,两阶段训练提升推理能力至工业级应用标准
240元打造擅长数学的多模态版R1,基于DeepSeek核心思想,两阶段训练提升推理能力至工业级应用标准多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。
来自主题: AI技术研报
6448 点击 2025-03-19 09:43
 搜索
搜索
多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。
CLIP、DINO、SAM 基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
OpenAI o1视觉能力还是最强,模型们普遍“过于自信”!

2月19日,界面新闻记者获悉,阿里AI To C业务近期开启大规模人员招聘,开放招聘岗位达到数百个,其中AI技术、产品研发岗位占比达到90%,所招聘人员将重点投入到文本、多模态大模型、AI Agent等前沿技术与应用的相关工作中。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。
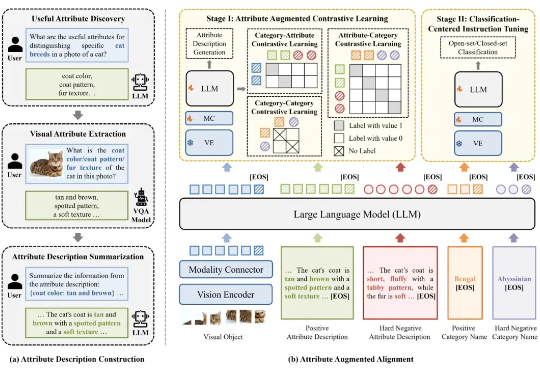
尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」