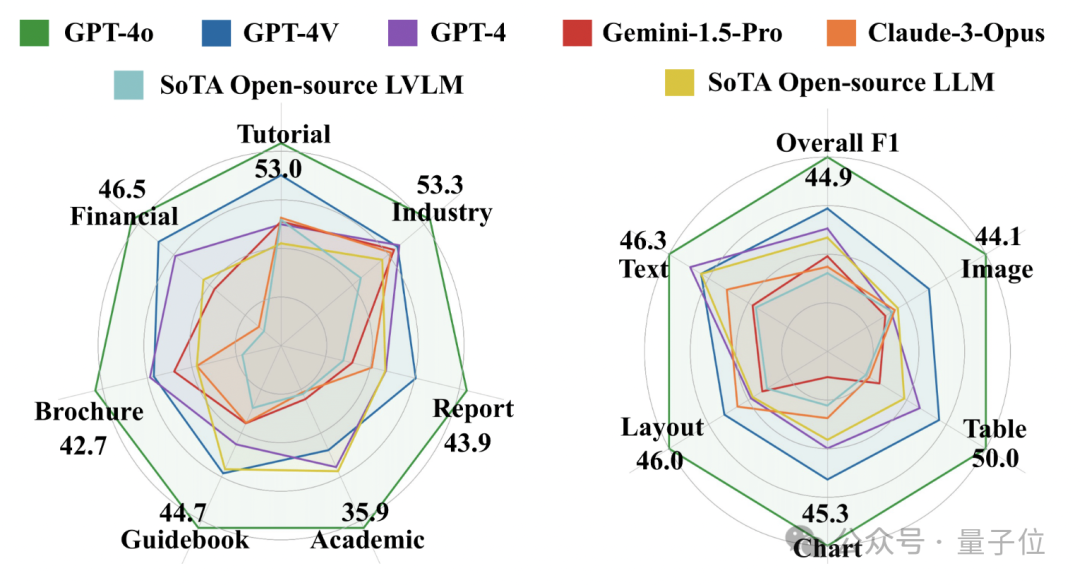
GPT-4o弱点暴露了,PDF长文档阅读理解仅45分
GPT-4o弱点暴露了,PDF长文档阅读理解仅45分图文并茂的PDF长文档在日常生活中无处不在。过去人们通常使用OCR,layout detection等方法对PDF长文档进行解析。但随着多模态大模型的发展,PDF长文档的端到端阅读理解成为了可能。
来自主题: AI技术研报
11065 点击 2024-08-03 14:38
 搜索
搜索
图文并茂的PDF长文档在日常生活中无处不在。过去人们通常使用OCR,layout detection等方法对PDF长文档进行解析。但随着多模态大模型的发展,PDF长文档的端到端阅读理解成为了可能。

国产多模态大模型,也开始卷上下文长度。

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。

开源多模态大模型或将开始腾飞。
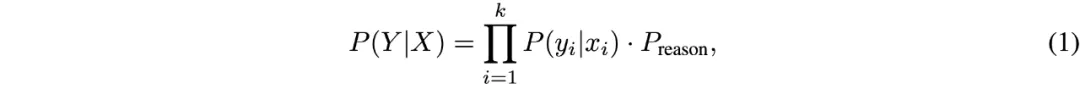
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。
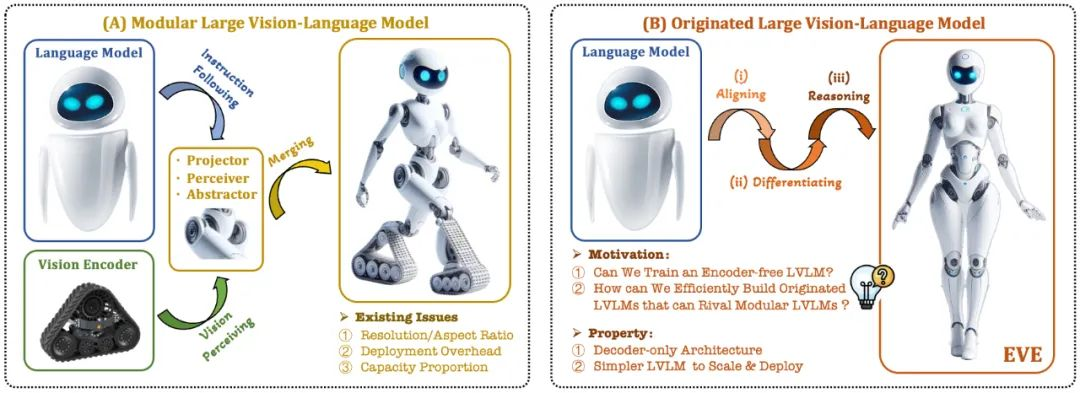
近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。
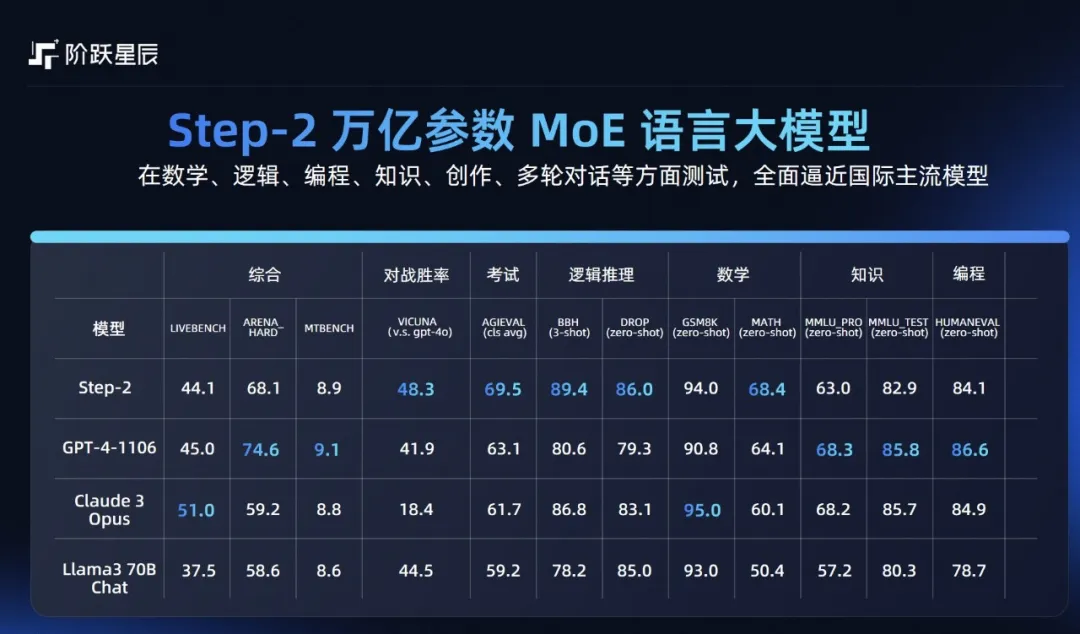
在今天揭幕的 2024 世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)上,阶跃星辰首发了三款 Step 系列通用大模型新品:Step-2 万亿参数语言大模型正式版、Step-1.5V 多模态大模型、Step-1X 图像生成大模型。

在 2024 年世界人工智能大会的现场,很多人在一个展台前排队,只为让 AI 大模型给自己在天庭「安排」一个差事。

GPT-4o或许还得等到今年秋季才对外开放。不过,由法国8人团队打造的原生多模态Moshi,已经实现了接近GPT-4o的水平,现场演示几乎0延迟,AI大佬纷纷转发。