爱诗科技获中国儒意1420万美元战略投资,视觉多模态大模型新突破!
爱诗科技获中国儒意1420万美元战略投资,视觉多模态大模型新突破!AI视频生成正从“静态输出”迈入“实时交互”阶段,一场内容创作革命即将到来。 近日,中国儒意宣布以1420万美元对爱诗科技进行战略投资,双方将围绕影视、流媒体、游戏等业务展开深度合作。 爱诗科技作为全
来自主题: AI资讯
10412 点击 2026-01-19 18:21
 搜索
搜索
AI视频生成正从“静态输出”迈入“实时交互”阶段,一场内容创作革命即将到来。 近日,中国儒意宣布以1420万美元对爱诗科技进行战略投资,双方将围绕影视、流媒体、游戏等业务展开深度合作。 爱诗科技作为全

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
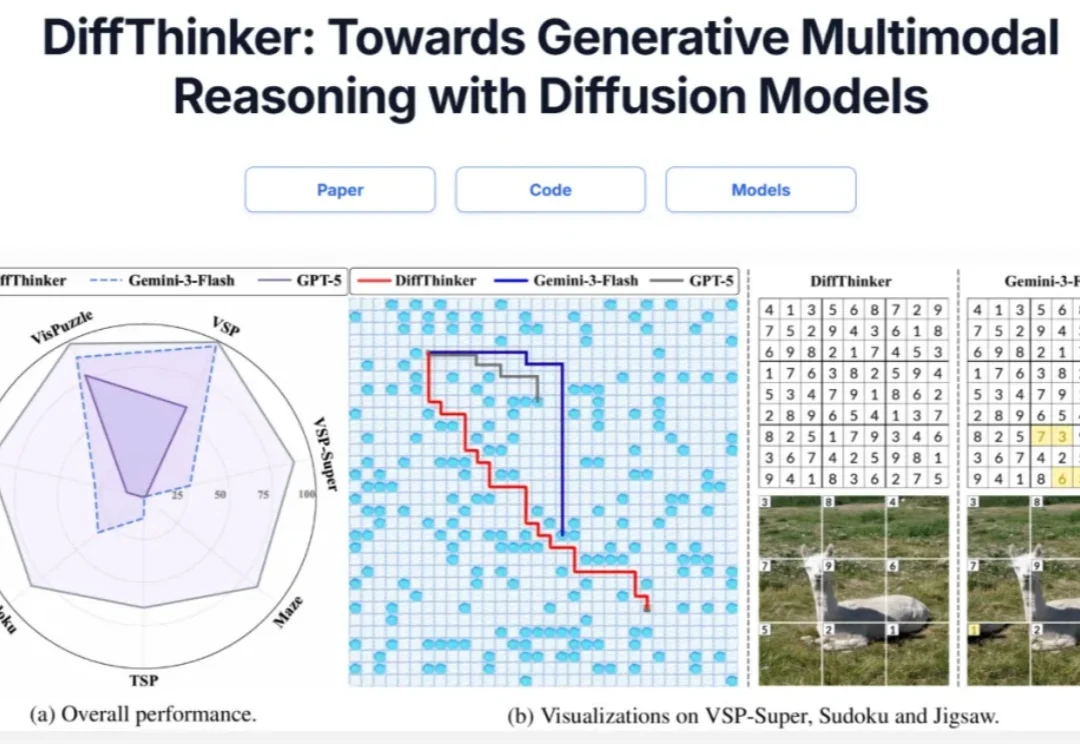
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
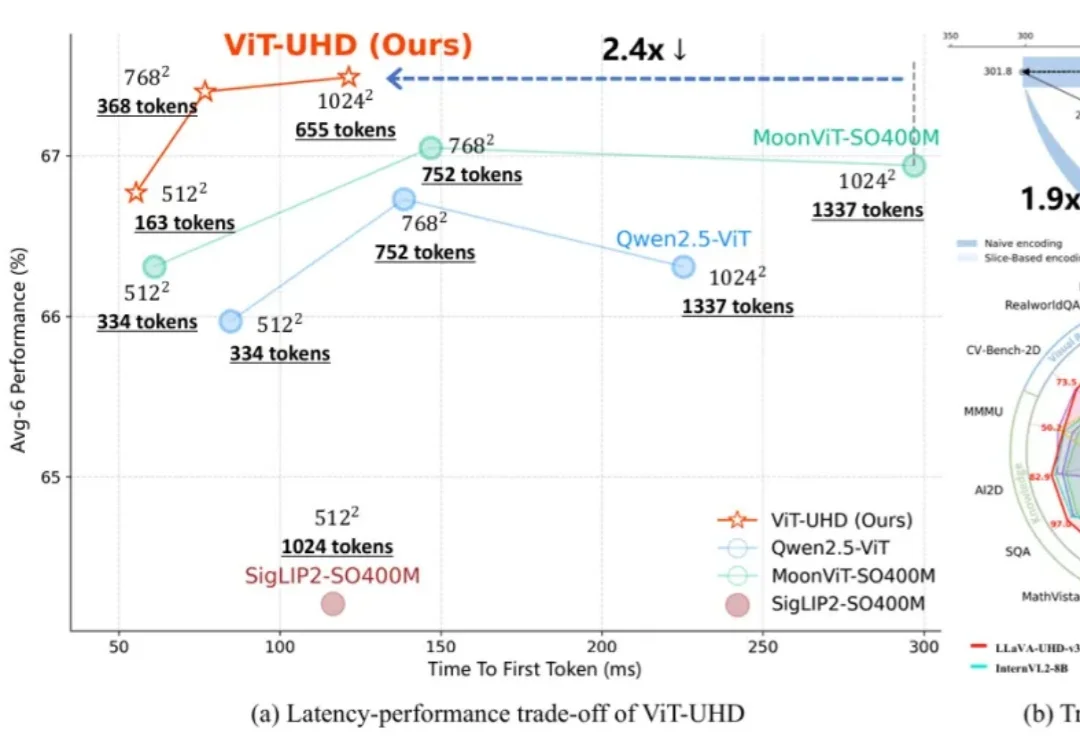
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。

国内记忆框架首开源,企业实战已上线运行。在海外巨头已经将“记忆系统”提升到基础设施层的同时,红熊AI便是其中之一。公司成立于2024年,围绕多模态大模型与记忆科学开展研发,并将这些能力用于为企业提供智能客服、营销自动化与AI智能体服务。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
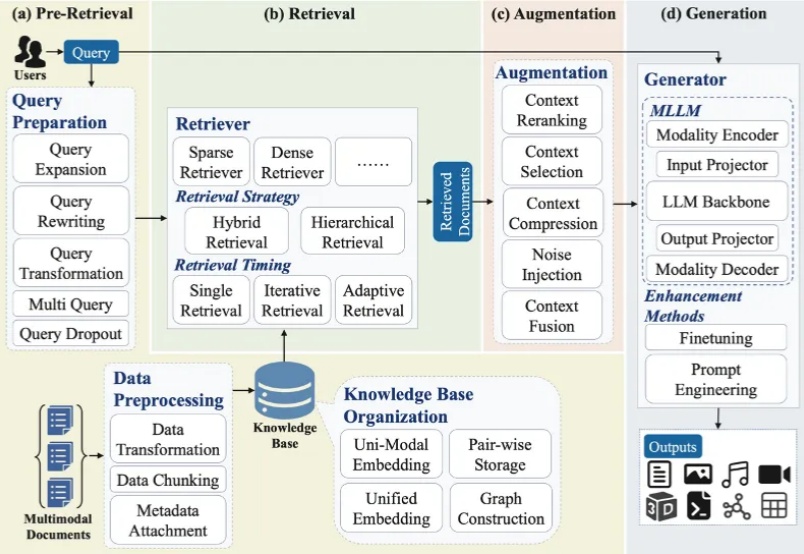
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。
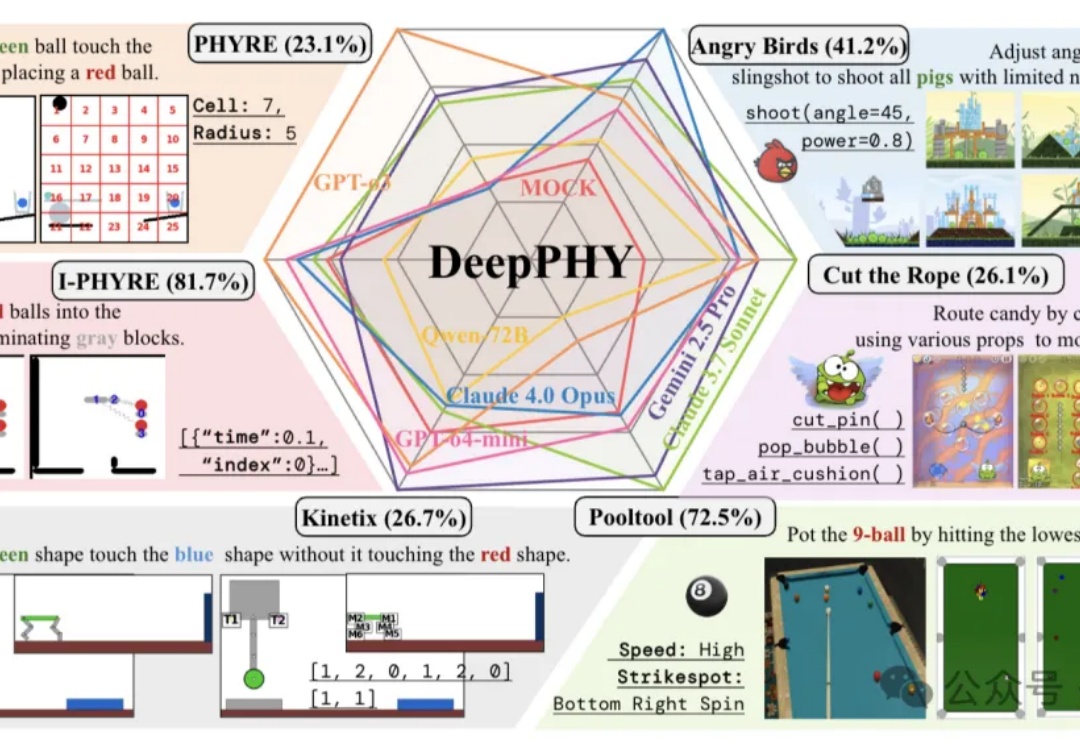
首个系统性评估多模态大模型(VLM)交互式物理推理能力的综合基准来了。
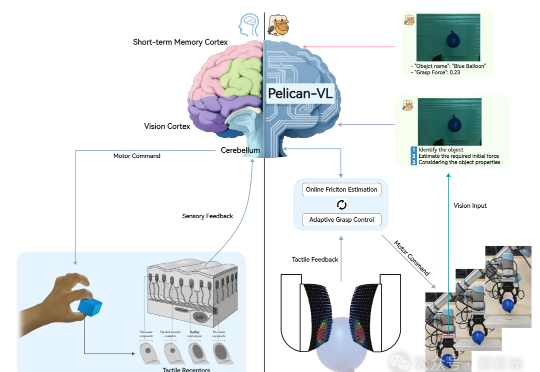
昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。