专访张祥雨:多模态推理和自主学习是未来的 2 个 「GPT-4」 时刻
专访张祥雨:多模态推理和自主学习是未来的 2 个 「GPT-4」 时刻本期内容是拾象 CEO 李广密对大模型公司阶跃星辰首席科学家张祥雨的访谈。
来自主题: AI资讯
9681 点击 2025-06-08 15:06
 搜索
搜索
本期内容是拾象 CEO 李广密对大模型公司阶跃星辰首席科学家张祥雨的访谈。
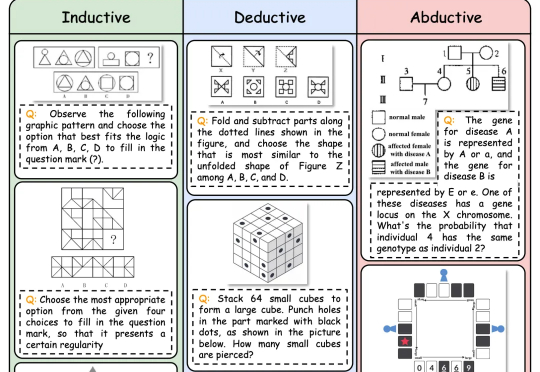
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
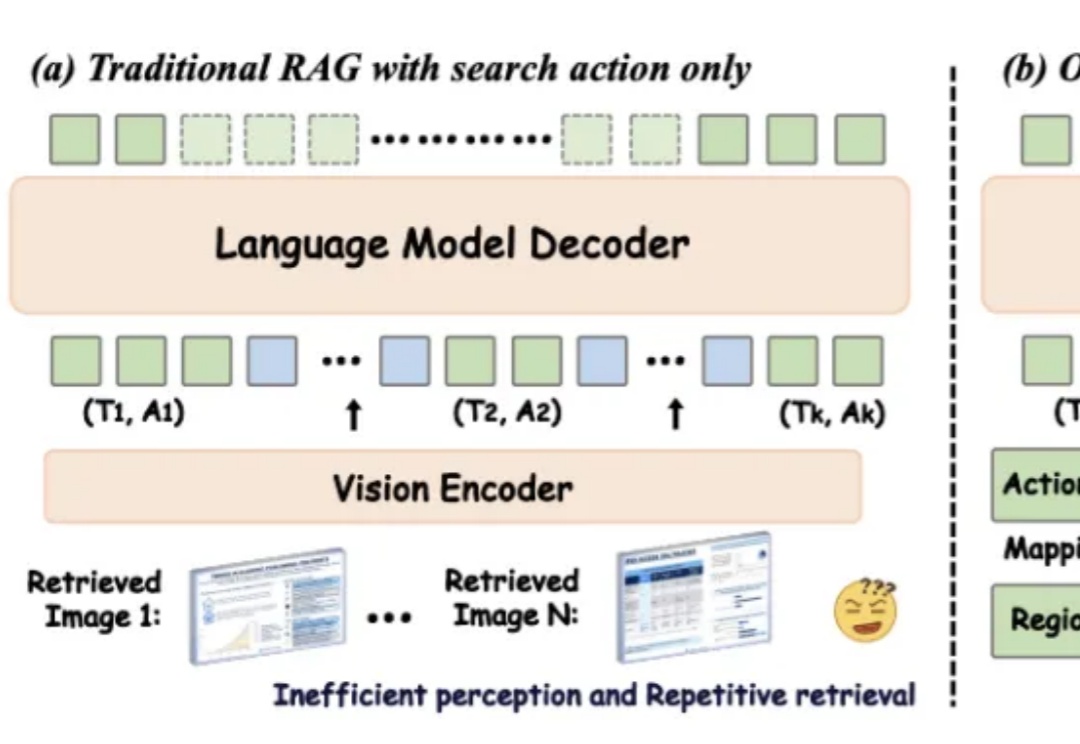
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。
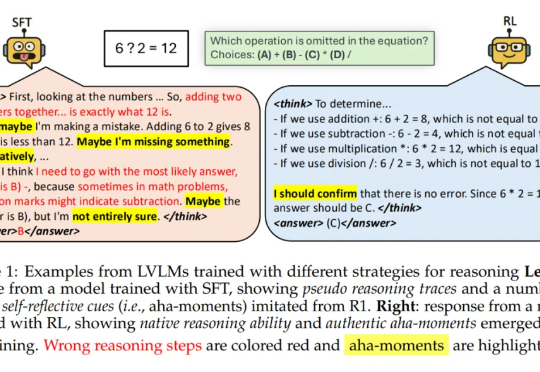
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」
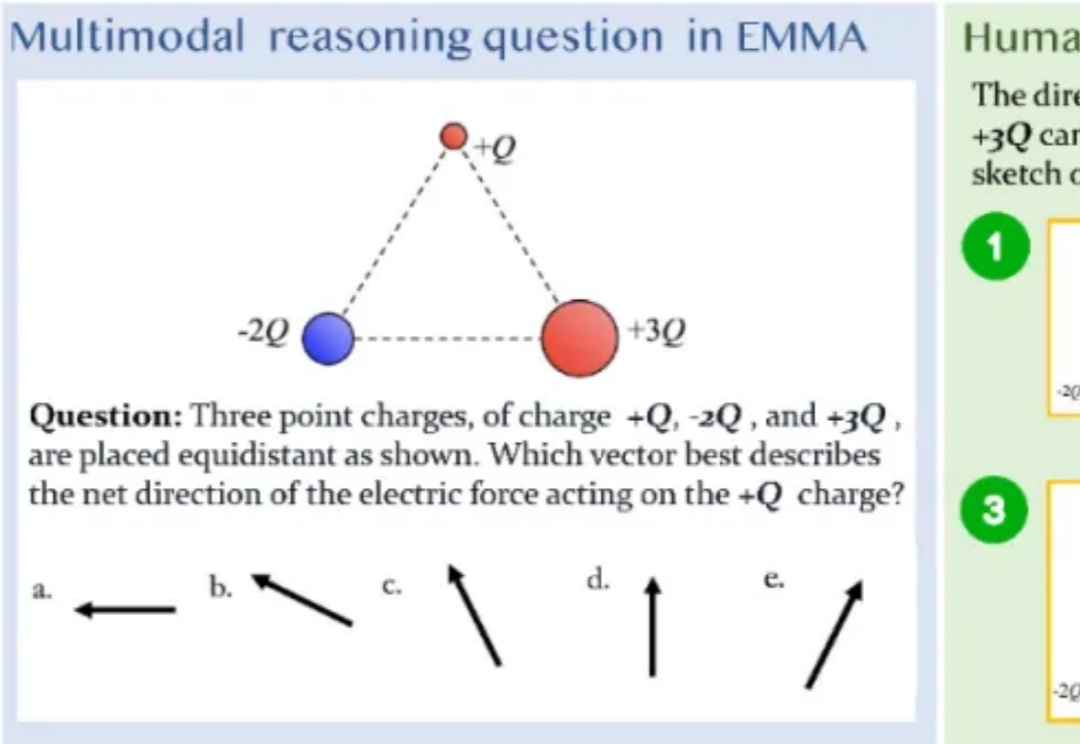
「三个点电荷 + Q、-2Q 和 + 3Q 等距放置,哪个向量最能描述作用在 + Q 电荷上的净电力方向?」
昆仑万维Skywork-R1V 2.0版本,开源了!这一次,它的多模态推理实现了再进化,成为最强高考数理解题利器,直接就是985水平。而团队也大方公开了各项技术秘籍,亮点满满。可以说,R1V 2.0已成为团队AGI之路上的又一里程碑。

全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
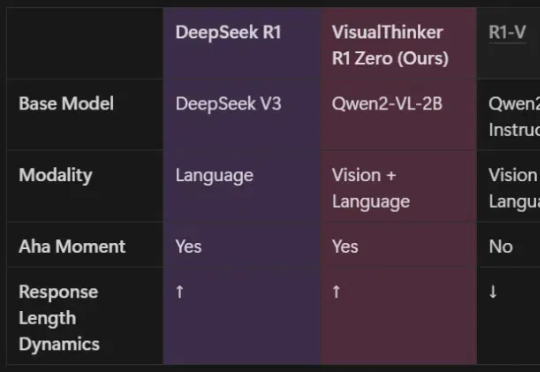
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!

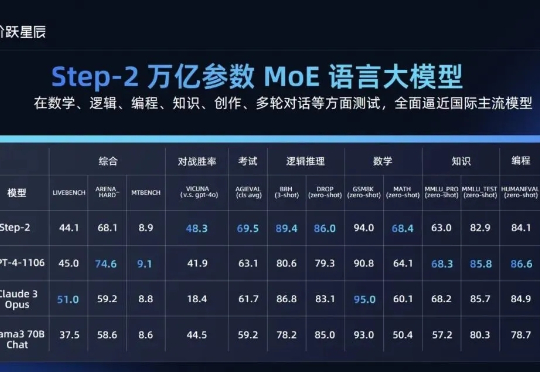
回应DeepSeek,阶跃星辰亮出“三件套”:开源,多模态推理,AI Agent。