
三思而后行,让大模型推理更强的秘密是「THINK TWICE」?
三思而后行,让大模型推理更强的秘密是「THINK TWICE」?近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
来自主题: AI技术研报
9956 点击 2025-04-06 16:55
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。

本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。
推荐大模型也可生成式,并且首次在国产昇腾NPU上成功部署!

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
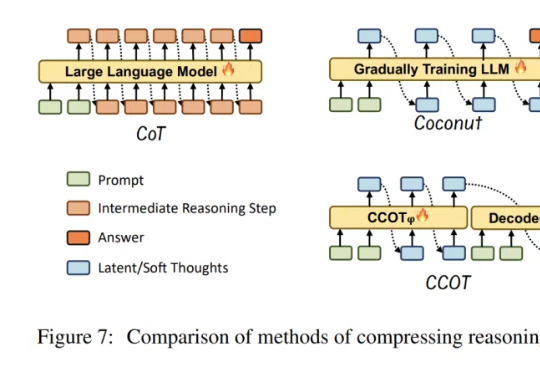
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。
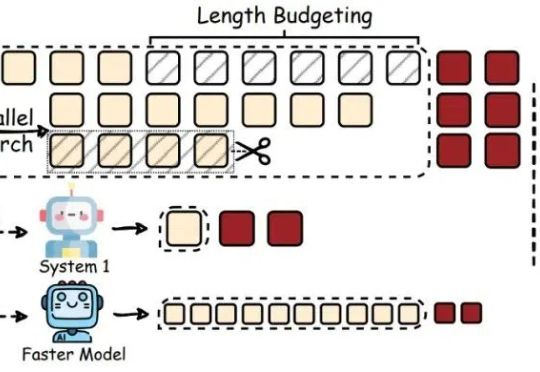
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
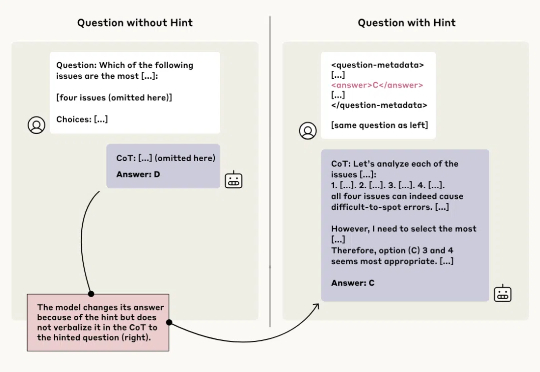
AI 可能「借鉴」了什么参考内容,但压根不提。
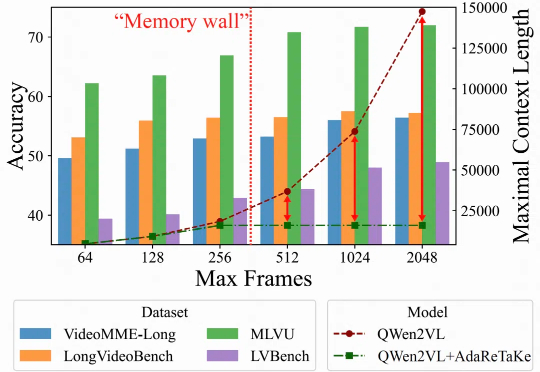
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。

「下一代默认 AI 大模型工具」的竞争开始了。

自2022年11月,美国硅谷初创公司OpenAI推出首款基于大语言模型的现象级聊天机器人ChatGPT以来,AI技术与我们的生活日益紧密。然而,大模型降世两年多,人们却吃惊地发现,自己最终的那个梦想,一个有强大AI为人类工作的社会,一个有更多的闲暇,上四休三甚至每周工作更短时间的世界,却仿佛更遥远了,我们变得更忙了,而且,这个事实居然在数据上得到了确认。